Long Context · Efficient AI · Transformers
End-to-End Context Compression at Scale with LCLMs
LCLMs train a 0.6B encoder and 4B decoder jointly to compress long context into soft tokens at 1:4, 1:8 and 1:16, cutting prefill memory and time-to-first-token while staying close to the uncompressed baseline.
Quick answer
Latent Context Language Models (LCLMs) compress long context by training a small encoder and a larger decoder together, end to end, instead of trimming the KV cache after the fact. A 0.6B Qwen3 encoder turns each block of N tokens into a single latent (soft) token, and a 4B Qwen3 decoder reads those latents at 1:4, 1:8, or 1:16 compression. Trained on roughly 350B tokens, the system pushes out the Pareto frontier across general-task accuracy, time-to-first-token, and peak GPU memory, and it stays close to the uncompressed 4B decoder on RULER and LongBench while spending a fraction of the prefill memory at long context.
How LCLM compression actually works
The encoder is Qwen3-Embedding-0.6B; the decoder is Qwen3-4B-Instruct. The input is cut into fixed blocks, each block is pooled into one continuous embedding (a soft token), and an MLP adapter projects those embeddings from encoder width into the decoder’s hidden size. The decoder then attends to the soft tokens as if they were normal input embeddings. Because there are 4x, 8x, or 16x fewer of them, the decoder’s prefill is shorter and its KV cache is smaller.
The word “end-to-end” carries the contribution. Earlier compression work usually freezes the language model and eviction or scoring happens around it. Here both encoder and decoder are trained together so the encoder learns what the decoder needs, not what a generic embedding objective rewards. That joint signal is why a 16x-compressed soft token can still carry enough of the original block to answer a question about it.
Two design choices matter more than they look. The encoder uses causal masking, which beat bidirectional in the architecture sweep, and the adapter is a plain MLP, which beat an attention-based adapter at lower cost. Pooling is not one-size-fits-all: mean pooling wins at 1:16, while concatenation wins at 1:4. The takeaway is that the right operator depends on how hard you are squeezing.
The training recipe and why both objectives are needed
The 350B-token budget is split across four stages: adapter warmup, encoder training, end-to-end continual pre-training, then supervised fine-tuning. The data mixes Nemotron text, code, and reasoning, plus a long-context slice and a reconstruction auxiliary task.
The reconstruction task is the part to notice. Training only on next-token prediction leaves the soft tokens too coarse to recover fine detail, but training only on reconstruction collapses the representations. Mixing both is what gives the latents enough fidelity to be useful and enough abstraction not to degenerate. This is the mechanism behind the accuracy that survives compression: the encoder is pushed to keep recoverable detail while the decoder is trained to use it for actual tasks.
Key results
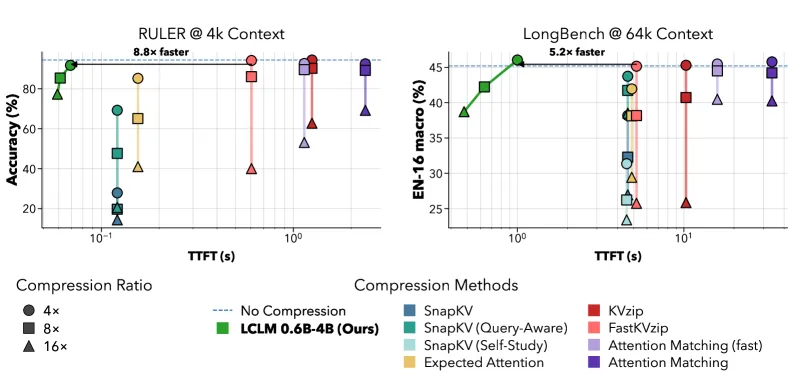
- Pareto frontier, not a single win. LCLMs improve the joint frontier of general-task accuracy, compression speed, and peak memory against KV-cache baselines including SnapKV, KVzip, and Attention Matching (Figure 1). The claim is relative position on that frontier, not a single headline accuracy number.
- Memory plateaus at long context. At high compression the LCLM peak GPU memory flattens as context grows, while baselines such as Attention Matching run out of memory near 512K to 1M tokens on the same hardware (Figure 4). This is the most concrete efficiency result.
- Compression time scales with ratio. KV-cache methods take a fixed time to compress regardless of ratio (vertical lines on the speed plot); LCLM compression gets faster as the ratio rises, so 1:16 is cheaper to produce than 1:4.
- Accuracy stays near the uncompressed decoder on RULER and LongBench at the tested ratios, with the gap widening as compression increases. The honest reading is that 1:4 is nearly free and 1:16 trades measurable accuracy for large memory savings.
- Selective expansion recovers retrieval. Giving an agent the full compressed context plus an EXPAND(i) tool that returns the original 512-token chunk substantially raises exact-match on needle-in-haystack and approaches the uncompressed baseline (Figure 6). Compression alone hurts precise retrieval; the tool buys it back.
Why this matters now
KV cache is the memory bottleneck for long-context inference, and most production fixes evict or quantize tokens after the model has already paid to encode them. LCLM moves the compression upstream into a trained encoder, so the decoder never sees the full sequence. For teams serving long documents or long agent histories, the appeal is a shorter prefill and a smaller cache without a separate eviction policy to tune. The selective-expansion result is the practical bridge: keep everything compressed for cheap context, expand only the chunks the model decides it needs.
Limits and open questions
The decoder still pays for what it reads. The encoder window is W=1024, so very long inputs are split across multiple encoder passes, and information that crosses a window boundary is split too; a boundary-overlap variant did not help. At very long context the decoder’s own prefill memory starts to dominate again, which caps how far the encoder-side savings carry.
Accuracy is not free at 1:16. The paper frames the result as a frontier, and the frontier exists because higher compression costs accuracy, most visibly on tasks needing exact recall. Anyone reading “16x compression” as lossless is overreading it.
The models are 0.6B and 4B. Whether the joint training recipe and the pooling choices transfer to much larger decoders, or to compression ratios past 1:16, is not shown. The EXPAND result also shifts cost back toward the original tokens, so the agent application is best read as a memory/precision dial, not a way to retrieve for free.
FAQ
What are Latent Context Language Models (LCLM)?
LCLMs are a family of context compressors that train a 0.6B encoder and a 4B decoder jointly. The encoder pools each block of input tokens into one soft token at 1:4, 1:8, or 1:16, and the decoder reads those soft tokens instead of the full sequence, cutting prefill time and KV-cache memory.
How does LCLM compare to KV-cache eviction like SnapKV and KVzip?
LCLM compresses upstream in a trained encoder, so the decoder never encodes the full sequence, while SnapKV and KVzip trim the cache after encoding. On the joint frontier of accuracy, compression speed, and peak memory, LCLM sits ahead of these baselines, and its memory plateaus at long context where Attention Matching runs out of memory near 1M tokens.
Does 1:16 LCLM compression lose accuracy versus the uncompressed model?
Yes, somewhat. LCLM stays close to the uncompressed 4B decoder on RULER and LongBench, but the gap grows with compression, and exact-recall tasks suffer most at 1:16. The 1:4 setting is nearly lossless; 1:16 trades measurable accuracy for large memory savings.
Why does LCLM train the encoder and decoder end-to-end instead of freezing the model?
Joint training lets the encoder learn what the decoder actually needs from a block rather than optimizing a generic embedding objective. Combined with a reconstruction auxiliary task mixed into next-token prediction, this keeps soft tokens detailed enough to answer questions while avoiding the representation collapse seen with reconstruction alone.
What does the EXPAND tool do in the LCLM agent setup?
EXPAND(i) returns the original uncompressed 512-token chunk for index i. The agent reads the whole compressed context cheaply, then expands only the chunks it needs, which substantially raises needle-in-haystack exact-match and approaches uncompressed retrieval accuracy.
One line: LCLM is a credible upstream alternative to KV-cache eviction for long context, strongest at moderate ratios and as a compressed-by-default agent memory, but 1:16 is a real accuracy-for-memory trade, not free compression. Read the original paper on arXiv.