DeNovoSWE:4818 个自动构建的仓库,训练整仓代码智能体
DeNovoSWE 自动构建 4818 个可验证的整仓生成任务。用它微调 Qwen3-30B-A3B,BeyondSWE-Doc2Repo 通过率从 0.058 升到 0.472。
快速答案
DeNovoSWE 既是数据集,也是训练配方,目标是训出能从规格说明写出整个仓库的代码智能体,而不是只改一个 bug。数据集有 4818 个实例,每个让模型从能力文档出发重建一个完整仓库,并自带可执行单元测试,所以结果能自动打分。用这份数据微调 Qwen3-30B-A3B-Instruct,在 BeyondSWE-Doc2Repo 上的通过率从 0.058 升到 0.472,35B-A3B 变体到 0.500。打分指标是通过的单元测试占比,在沙箱 Docker 里多次 rollout 取均值。诚实的说法:这是小模型在一个很难的新任务上的微调收益,不是前沿结果——GPT-5.4(0.563)、GLM-5(0.568)这类闭源模型分数仍然更高。
这个任务到底是什么
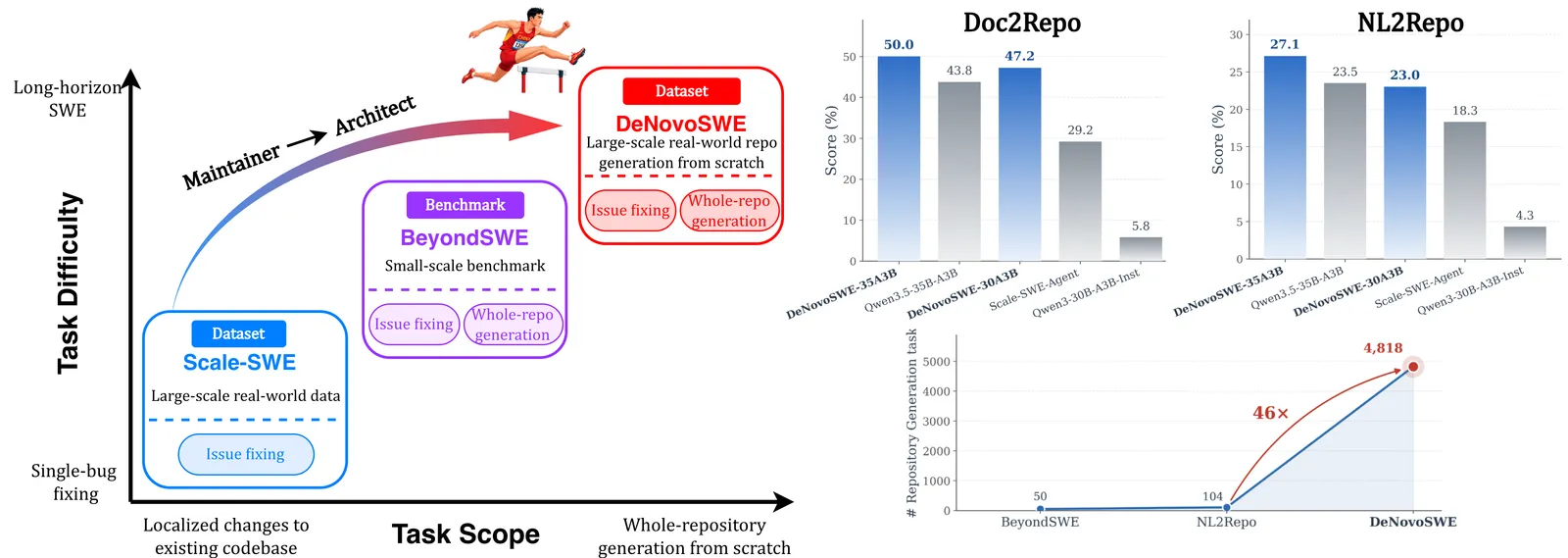
多数 SWE 训练数据是局部的:SWE-bench 那类 issue 给模型一个能跑的仓库,让它产出一个补丁。DeNovoSWE 走的是另一个极端。模型只拿到能力文档,要产出整个仓库,文件结构、实现、全部,产物要能跑通项目的测试。最接近的前作 NL2Repo 只有 104 个实例;DeNovoSWE 大约是它的 46 倍,有 4818 个。这正是关键,因为长程整仓生成恰恰是几百个样本教不会模型的那种规模。
这个任务的麻烦在验证。补丁可以拿一个已知正确的测试套件来检验。从零写的仓库在你建出来之前没有测试套件,而由写代码的同一个模型来写测试又是循环论证。DeNovoSWE 的构建,大半是在回答这个问题。
仓库怎么自动构建
整条管线用分治加批评修复的流程,从真实仓库里反推任务,不用人工标注。
分(divide)阶段把源仓库切成若干功能能力。它跑现有单元测试,追踪运行时,把每个函数或类标为对该能力直接、核心间接、还是非核心间接,再用一个 LLM 分类器把组件映射到能力上。治(conquer)阶段构建充当任务提示词的文档:草稿 agent 在对源码只读的沙箱里写出初版能力文档,批评 agent 标出结构、覆盖、API 规格上的缺口,修复 agent 把这些缺口补上。各能力的文档合并成一份仓库级规格。
因为测试来自原仓库,不是来自生成模型,验证就有了根。生成的仓库按它通过多少条原始测试来打分,绕开了循环。但这也意味着任务是”重建一个已存在的仓库”,而非”凭空发明一个新仓库”,这点 benchmark 名字(Doc2Repo)说得很诚实。
打分和防泄漏怎么做
每个实例按通过测试数除以总测试数打分,多次 rollout 取均值,全程在限制了网络和包访问的 Docker 沙箱里跑。值得看的工程在防泄漏,因为参考仓库实实在在躺在构建环境里,偷懒的 agent 直接抄就行。DeNovoSWE 清掉 site-packages 痕迹、隐藏的 pip wheel 缓存和编译产物;销毁并重新初始化 .git,让 agent 没法从 reflog 或游离对象里捞回原始代码;还拦掉指向参考仓库的 clone、pip install、curl/wget,并用 LLM-as-judge 审计执行轨迹查作弊。这部分是复用这份数据的人最该细读的,因为一个马虎的重实现会在这里悄悄虚高分数。
关键结果
- Qwen3-30B-A3B-Instruct:在 BeyondSWE-Doc2Repo 上 0.058 升到 0.472,经 DeNovoSWE 微调后。这是相对 8 倍的跳升,也是头条结论。这里的通过率是单元测试通过的平均占比,不是整仓全有全无。
- 35B-A3B 变体:0.438 升到 0.500。 更强的底座起点就高(0.438),绝对增益更小,所以那个夸张的提升大半是把一个弱底座救起来,而非普遍的大效应。
- 仍低于前沿闭源模型: GPT-5.4(CodeX)0.617,GLM-5 0.568,DeepSeek-V4-Pro 0.566,GPT-5.4 0.563,Gemini3-Pro 0.520。DeNovoSWE-Agent-30A3B(0.472)追近了很多,但没追过它们。
- 胜过此前的 agent 基线: Scale-SWE-Agent 是 0.292;微调后的 30B-A3B 以小得多的规模拿到 0.472。
- 难度感知过滤有帮助,但有限: 按实例定阈值(最易 0.90 到最难 0.60,用与实测通过率的 Pearson 相关性调出来)拿到 0.500,最佳固定阈值是 0.488。团队在难实例上保留部分成功的轨迹,因为完全成功的 rollout 很少见。
- 规模:4818 个实例,约为 NL2Repo 104 个的 46 倍。 贡献是在一个此前数据太薄、没法训练的任务上做出了体量。
局限与存疑
这个 benchmark 测的是重建,不是发明。Doc2Repo 让模型重建一个文档由它自己的测试反推出来的仓库,所以高分证明模型能重建一个有文档的代码库,不证明它能从模糊的产品规格里架构出新东西。通过率是按测试条算的,所以 0.472 不代表 47% 的仓库能端到端跑起来;部分得分会相对严格的全测试通过门槛把数字抬高。论文没给构建管线(每个实例要跑好几个 LLM agent)或评测时长程 rollout 的 token、墙钟、费用,所以这套数据生成回路的效率没有实测。防泄漏措施具体且用心,但它的完备性押在 LLM-as-judge 审计上,而后者本身没拿对抗性 agent 验证过。复现取决于承诺开源的数据集和构建代码;没有难度权重的调参配方,0.500 那个消融结果很难重建。
常见问题
DeNovoSWE 是什么,覆盖什么任务?
DeNovoSWE 是一套整仓生成的数据集加微调配方:从能力文档产出整个代码库,而不是改一个 bug。它有 4818 个自动构建的实例,每个带可执行单元测试用于打分,用来训练 Qwen3-30B-A3B 这类长程 SWE 智能体。
DeNovoSWE 怎么把 Qwen3-30B-A3B 在 BeyondSWE-Doc2Repo 上从 0.058 拉到 0.472?
靠在 4818 个 DeNovoSWE 实例上做监督微调。底座 Qwen3-30B-A3B-Instruct 在 BeyondSWE-Doc2Repo 上通过率 0.058;在 DeNovoSWE 轨迹上训练后到 0.472。指标是多次 rollout 通过单元测试的平均占比,不是整仓成功率。
DeNovoSWE 的 0.472 在整仓生成上比 GPT-5.4 强吗?
不。DeNovoSWE-Agent-30A3B 是 0.472,而在同一个 BeyondSWE-Doc2Repo 上,GPT-5.4(CodeX)0.617,普通 GPT-5.4 0.563。这是小模型一次很强的微调收益,缩小了与闭源模型的差距,不是超越前沿的分数。
DeNovoSWE 怎么防止 agent 抄参考仓库?
构建沙箱清掉 site-packages 痕迹、pip wheel 缓存和编译产物,销毁并重新初始化 .git 让原始代码没法从 reflog 或游离对象里捞回,还拦掉指向参考仓库的 clone/pip install/curl,并用 LLM-as-judge 审计执行轨迹查作弊。
DeNovoSWE 是数据集论文还是训练方法?
两者都是。数据集是 4818 个自动构建、可验证的实例;方法是分治加批评修复的构建管线,以及用于在长程整仓生成上微调小代码模型的难度感知轨迹过滤。
关于长程代码智能体如何探索和行动的上下文,可看 SWE-Explore 讲仓库探索,以及同批的 Orchestra-O1 讲智能体编排、Beyond Uniform Token Trust Region 讲智能体的 RL。
一句话:DeNovoSWE 表明整仓生成这个最难的长程 SWE 任务,能变成 4818 个自动验证的训练样本,在不靠前沿底座的前提下把一个弱 30B 模型抬高 8 倍。阅读 arXiv 原文。