高效 AI · 长上下文 · Transformer
全注意力反击:RTPurbo 几百步把大模型转成稀疏注意力
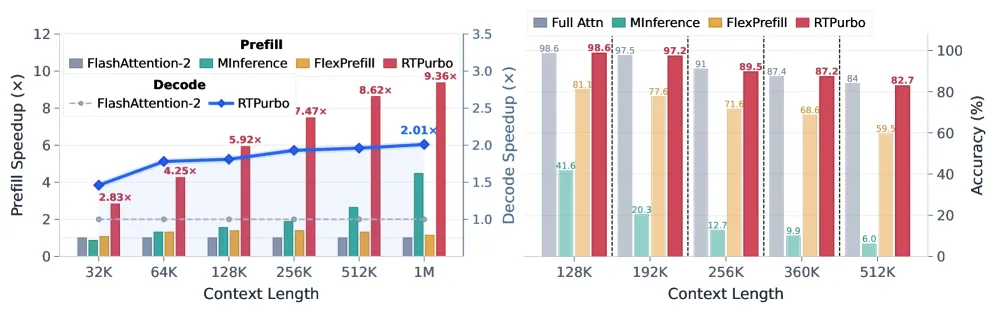
RTPurbo 用两阶段各约 600 步,把训练好的全注意力大模型转成稀疏注意力,LongBench 54.24 反超 53.80,1M 上下文预填充提速 9.36 倍。
快速答案
RTPurbo 把一个已训练好的全注意力大模型,用两个各约 600 步的短适配阶段转成稀疏注意力模型——不是从零预训练——结果质量不掉,长输入上却快得多。在 Qwen3-Coder-30B-A3B 上,1M token 上下文的预填充提速达 9.36 倍,解码约 2.01 倍,而 LongBench 平均分反而从全注意力基线的 53.80 微升到 54.24。诀窍在于:只有 15% 的注意力头保留全上下文,其余 85% 跑 8192 token 的滑动窗口加 4 个 sink token。
没人用过的稀疏性:注意力头分工
出发点是:训练好的模型里,注意力头早已分工。少数头做长程检索——真正回看整段上下文——而大多数头只关注局部。以往的稀疏注意力工作,要么把稀疏性塞进去重训整个模型,要么对所有头套同一种稀疏模式,前者贵,后者要么浪费检索头的回看能力、要么让局部头拿不到提速。RTPurbo 改为逐头测量并分配角色:约 15% 留作全上下文检索头,其余转成固定滑动窗口。标题「全注意力反击」正是这个意思——你不丢弃训练好的全注意力模型,而是把它迁移过来。
RTPurbo 怎么做
整条管线刻意做得很便宜。第一阶段训练一个 16 维低秩索引器,让检索头挑选回看哪些更早的 token,约 600 步收敛,耗约 30M token。第二阶段做端到端自蒸馏——稀疏模型学着对齐原全注意力模型的输出——约 600 步收敛,其中真正参与学习的标签 token 仅约 120 万。所以标题里「几百步」对每个阶段的量级是真实的,只是诚实的总数更接近两阶段合计约 1200 步。相比从零预训练一个稀疏模型,这点开销可以忽略,而这正是论文的核心卖点。
关键结果
- 预填充提速 9.36 倍:Qwen3-Coder-30B-A3B 在 1M token 上下文下;同长度解码约 2.01 倍;在更常见的 32K 上下文下预填充提速为 2.83 倍。
- LongBench:平均 54.24 对 53.80(全注意力基线)——稀疏模型略微反超自己的老师,是论文中最硬的结果。
- RULER 64K:85.49 对 86.23——小幅、诚实的下降,而非持平。
- AIME24/25:86.67%,在 Qwen3-30B-A3B-Think 上与全注意力完全一致,推理任务扛住了稀疏化。
- 结构: 15% 检索头(全上下文)、85% 滑动窗口头(窗口 8192,外加 4 个 sink token)、检索用 16 维索引器。
为什么现在重要
长上下文推理被注意力开销卡死,而多数团队负担不起从零训一个稀疏模型。RTPurbo 给出一条复用现有强 checkpoint 的路径,只付几百步代价,就让它在 1M token 下变便宜。真正值得关注的是近乎无损的 LongBench 与 AIME 数字:不少稀疏注意力论文秀提速,却在硬长上下文任务上悄悄掉几分。在 LongBench 上略超基线、同时保住推理准确率,比「下降可忽略」是更强的主张。
局限与存疑
诚实都藏在细节里。其一,方法依赖稳定的头分工——若某模型的头没有干净地分成检索头和局部头,或领域漂移挪动了这个划分,固定的 15%/85% 分配未必成立。其二,预填充并未完全稀疏化:检索头在预填充阶段仍跑稠密注意力,所以预填充提速虽大,却到不了理论上限。其三,评测集中在 Qwen3 系列以及长上下文加推理任务;作者自己也说,还需要在其他架构和领域上更广泛地验证。9.36 倍这个标题数是 1M 上下文的成绩——在多数人实际用的 32K 下,收益是更温和的 2.83 倍。
常见问题
RTPurbo 是什么,能做什么?
RTPurbo 是南京大学与阿里巴巴的框架,用两个各约 600 步的短适配阶段,把训练好的全注意力大模型迁移成按头稀疏注意力模型,而非从零重训。它让约 15% 的头保留全上下文,其余跑滑动窗口。
RTPurbo 在长上下文下能快多少?
在 Qwen3-Coder-30B-A3B 上,1M token 上下文的预填充提速达 9.36 倍,解码约 2.01 倍;在 32K 上下文下预填充提速为 2.83 倍。
RTPurbo 相比全注意力会掉精度吗?
几乎不掉,在 LongBench 上还略升:平均 54.24 对全注意力的 53.80。RULER 64K 小幅降到 85.49(原 86.23),AIME24/25 与全注意力持平在 86.67%。
RTPurbo 为什么叫「全注意力反击」?
因为它不丢弃训练好的全注意力模型——而是用很低成本把它迁移成稀疏模型,并保留少数全上下文检索头,让长程能力得以存活。
一句话:复用一个强全注意力 checkpoint,花几百步,就能以最高 9.36 倍预填充提速跑 1M token 上下文且近乎无损。阅读 arXiv 原文。