LLaDA:用掩码扩散硬刚 LLaMA3 的 8B 语言模型
LLaDA 用掩码扩散取代下一个词预测,8B 模型在上下文学习上与 LLaMA3 8B 持平,GSM8K 拿 70.7,反向补诗任务还反超 GPT-4o。
快速答案
LLaDA 是一个 8B 参数的语言模型,它彻底抛弃了「下一个词预测」,改用反转掩码过程来生成文本——和图像扩散同一套思路,搬到了离散 token 上。它从零在 2.3 万亿 token 上训练,上下文学习与 LLaMA3 8B 持平,GSM8K 拿到 70.7(LLaMA3 8B 为 53.1),MMLU 为 65.9(对 65.4),最惊人的是在反向补诗任务上反超 GPT-4o(42.4% 对 34.3%)——这正是自回归模型一直没干净解决的弱点。它是「大语言模型必须是自回归」这一假设其实只是选择、不是定律的第一份有力证据。
扩散语言模型到底怎么工作
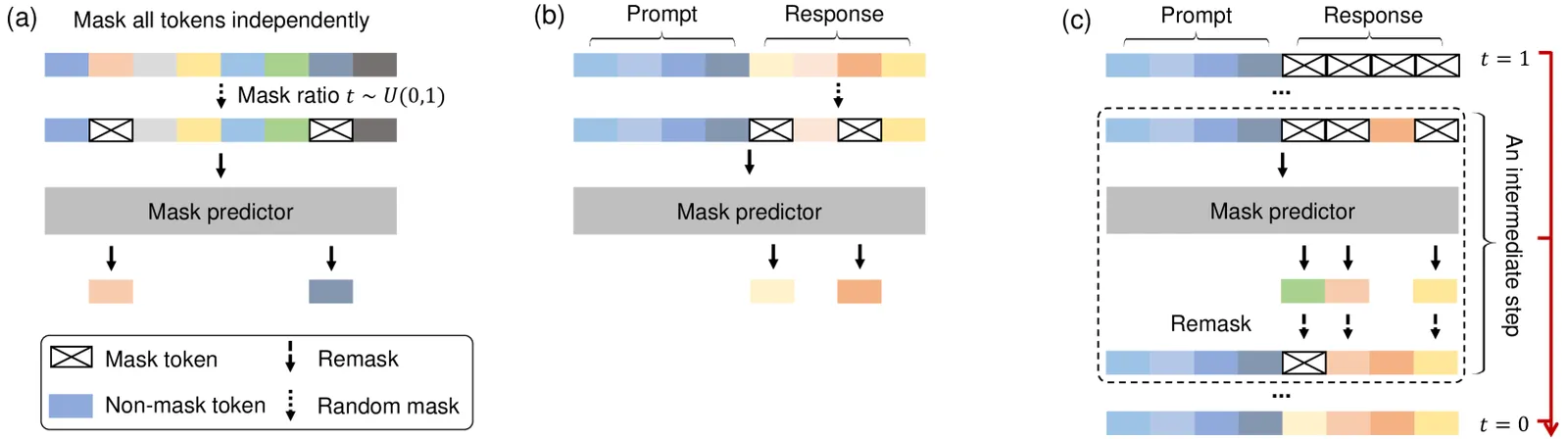
自回归模型从左往右写:用第 1…i−1 个 token 预测第 i 个。LLaDA 完全不这么干。它定义一个前向掩码过程:在一个 0 到 1 之间随机抽取的比例 t 下,把每个 token 独立地替换成 [MASK]。一个普通 Transformer——也就是掩码预测器——被训练成一次性还原所有被掩码的 token。生成时,从全掩码序列出发反向运行:预测、保留有把握的 token、把其余重新掩码,在固定步数内反复迭代,直到没有掩码为止。
它的训练目标不是自回归似然,而是掩码扩散对数似然的下界。这点很关键:它意味着 LLaDA 是一个有真实似然的、有原理可循的生成模型,而非启发式拼凑。作者正是靠这点论证扩散应当能 scale,然后用实验证明它确实能。
关键结果
- GSM8K(数学,4-shot): LLaDA 8B Base 拿 70.7,LLaMA3 8B Base 为 53.1——是大幅领先,不是勉强追平。
- MMLU(5-shot): 65.9 对 65.4,与 LLaMA3 8B 基本打平。
- 反转诅咒: LLaDA 8B Instruct 在反向补诗任务上 42.4%,GPT-4o 为 34.3%。由于掩码是对称的,LLaDA 没有天生的从左到右偏置,「倒着补全」对它在结构上并不更难。
- token 效率: 它只用 2.3T 训练 token、0.13M H800 GPU 小时,就达到与 LLaMA3(报告的 15T token)相当的质量。
- scaling: 在不同算力规模上,LLaDA 紧贴作者自建的自回归基线,并在 MMLU 与 GSM8K 上反超——核心主张是「scaling 上有竞争力」,而不只是单个强 checkpoint。
相比以往扩散语言模型,新在哪
文本离散扩散并不新鲜,缺的是规模和一场公平较量。早期的掩码 / 离散扩散语言模型参数远不到 1B,也从没在前沿规模的 token 预算上训练过,所以没人能说清这套方法到 8B 会不会崩。LLaDA 是第一个把纯掩码扩散 LLM 从零推到 8B,并和同配方自回归基线正面对打的工作。反转诅咒的结果是结构性收益最干净的证明:不是 LLaDA 更聪明,而是双向目标移除了一个自回归模型天生就背的失败模式。
局限与存疑
最诚实的隐患是推理。LLaDA 在固定步数的去噪上生成,质量与步数相互权衡——没有便宜的一次性解码,也没有成熟的 KV-cache 对应物,所以相比调优过的自回归服务栈,单 token 成本和延迟是真实问题。Instruct 版在若干对话 / 指令基准上仍落后 LLaMA3 8B Instruct(差距小但存在),部分原因是它的后训练配方远不如自回归模型那几年 RLHF 打磨得成熟。当你往一块固定大小的掩码画布上采样时,变长和开放式生成会很别扭。而且「与 LLaMA3 8B 有竞争力」是这里展示的上限、不是领先——这是 8B 规模上的可行性证明,还不构成切换生产栈的理由。
为什么现在重要
在大模型时代的大部分时间里,「语言模型」默默地等同于「自回归 Transformer」。LLaDA 是迄今最强的一个反例数据点:这只是工程默认值、不是硬性要求——一个非自回归模型能在同一批基准上、在 8B 规模站稳脚跟。它重新打开了行业已经不再探索的设计空间:并行多 token 生成、原生双向上下文、可控填空。反转诅咒这一胜利正是值得这趟绕路的那种质的差别,而且它恰好出现在扩散语言模型的后续工作(分块变体、MoE 扩散 LLM)开始冒头之时——LLaDA 是它们共同引用的参照点。
常见问题
LLaDA 是什么?
LLaDA(Large Language Diffusion with mAsking,带掩码的大语言扩散)是一个 8B 参数语言模型,它通过反转一个 token 掩码扩散过程来生成文本,而不是从左到右预测下一个词。它从零在 2.3 万亿 token 上训练。
LLaDA 和 LLaMA3 8B 比怎么样?
上下文学习上有竞争力:基座模型 MMLU 为 65.9 对 65.4、GSM8K 为 70.7 对 53.1,且训练 token 更少(2.3T 对 15T)。指令微调后的 LLaDA 在部分对话基准上仍略逊于 LLaMA3 8B Instruct。
LLaDA 怎么破解反转诅咒?
它训练时对称地掩码 token,没有从左到右的顺序,所以「用后文预测前文」在结构上并不更难。在反向补诗任务上 LLaDA 8B Instruct 拿 42.4%,GPT-4o 为 34.3%。
LLaDA 比自回归模型更快吗?
不一定。它在固定步数的去噪上生成,输出质量取决于步数,所以推理成本和延迟是已知短板,而非加速点。
扩散语言模型为什么重要?
它表明大模型的核心能力并非天生依赖自回归建模,从而在人们真正会用的规模上,重新打开并行生成、双向上下文等非自回归设计选项。
一句话:一个掩码扩散 8B 模型能追平自回归 8B,甚至修好反转诅咒——但代价在推理。阅读 arXiv 原文。