Arbor:用假设树管理自主科研
Arbor 用持久假设树管理科研尝试,6 个 AO 任务 held-out 结果全胜,MLE-Bench Lite Any Medal 达 86.36%。
快速答案
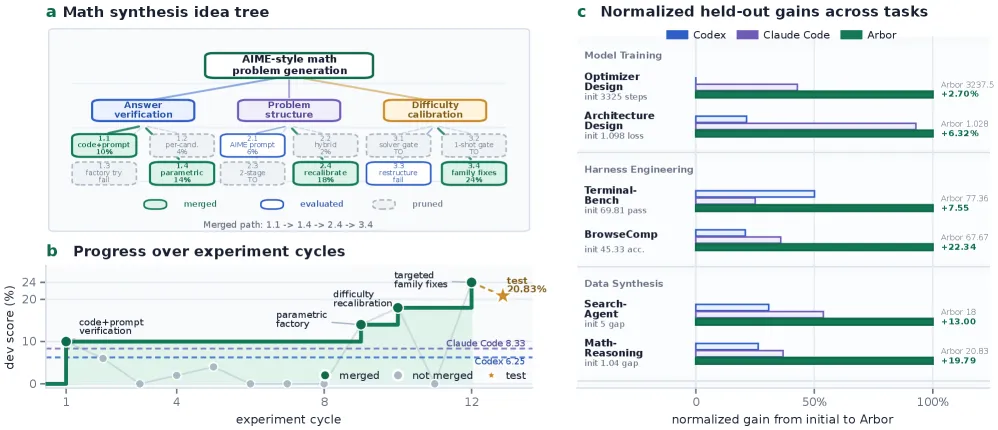
Arbor 是一套自主科研框架,核心是 Hypothesis Tree Refinement(HTR)。一个长期运行的 coordinator 维护假设、代码工件、实验证据和经验总结组成的树;短期 executor 每次只在隔离 worktree 里测试一个假设。论文最重要的结果是:Arbor 在 6 个真实 Autonomous Optimization(AO)任务上都取得最佳 held-out 结果,平均相对 held-out gain 超过同接口同预算下 Codex 和 Claude Code 的 2.5 倍。用 GPT-5.5 跑 MLE-Bench Lite 时,Arbor 达到 86.36% Any Medal。
为什么这篇值得补
很多「AI 科学家」系统本质上还是流水线:生成想法、写代码、跑实验、总结结果。Arbor 的判断更清楚:长程科研失败常见于状态管理失败。智能体忘了前面实验真正证明了什么,反复追 dev set 分数,或者无法说明某个分支为什么应该替换当前最好版本。
所以这篇论文的重点不是又做了一个科研机器人,而是问长程研究过程中什么东西应该被长期保存。Arbor 的答案是假设树,不是越来越长的聊天上下文。每个节点绑定一个假设、一个 artifact 版本、一组实验结果、一个分数和一条可复用经验。
HTR 怎么运作
Coordinator 负责整棵树。它决定哪些 frontier 节点该展开,哪些方向该剪掉,以及什么时候把候选分支提升为当前最好版本。Executor 是短期工作者:拿到一个假设,在隔离 worktree 中实现,跑评测器,再返回压缩后的结果报告。
真正关键的是 merge gate。开发集反馈可以用于搜索,但工件层面的进展只有通过 held-out evaluator 才能被接纳。这是论文防止 metric chasing 的核心机制。一个分支在探索阶段看起来有效,如果不能超过 held-out 上的当前最好结果,仍然不会被合并。
关键结果
- 6 个 AO 任务: Arbor 在模型训练、harness engineering、数据合成三类真实任务上都拿到最佳 held-out 结果。
- 相对收益: 论文报告 Arbor 的平均相对 held-out gain 超过 Codex 和 Claude Code 的 2.5 倍。
- MLE-Bench Lite: Arbor + GPT-5.5 达到 86.36% Any Medal,是对比中最强结果。
- 消融: Claude Opus 4.6 backbone 下,完整 Arbor 在 MLE-Bench Lite 上为 81.82% Any Medal;去掉树降到 63.64%,去掉 insight feedback 降到 54.54%。
- 预算: 6 个完整成本日志里,Arbor 使用 20.12M 到 43.19M tokens,作者认为与单轨迹 baseline 大致同量级。
最干净的证据是消融。树结构不是只让程序跑起来,而是在已有可运行方案之后帮助系统判断哪些方向值得继续细化。
该怎么诚实理解
Arbor 最适合有可执行评测器、清晰 dev/test 切分、且工件可持续改进的任务。ML 工程和 benchmark harness 正好符合这个条件。它不能直接代表开放理论研究、湿实验科学,也不能代表需要长期多人协作和主观判断的科研工作。
论文也明确说这是持续更新的 technical report。这有好处,系统和评测会继续扩展;但读者应把当前数字视为强项目报告,而不是已经稳定下来的通用科研基准。更值得吸收的是协议:假设、代码分支、证据和合并决策都应可审计。
局限与存疑
6 个 AO 任务是真实任务,但科学空间仍然很窄。和 Codex、Claude Code 的比较有价值,因为它们是强通用编码智能体;不过结果仍可能受接口、评测器、时间上限和 artifact 定义影响。成本也不能忽略,即便 token 用量与 baseline 接近,更大任务可能让树的增长难以控制。
最大问题是:当反馈延迟、噪声大或带主观性时,HTR 还是否有效? 如果每个分支都要专家评审,held-out merge gate 本身就会成为瓶颈。
常见问题
Arbor 在自主科研里是什么?
Arbor 是一套自主科研框架,用 coordinator、短期 executor 和持久假设树,通过反复实验改进研究工件。
Hypothesis Tree Refinement 是什么?
HTR 把每次研究尝试存成树节点,节点包含假设、artifact 版本、证据、分数和总结出的 insight。这棵树同时是记忆、搜索前沿和审计记录。
Arbor 比 Codex 和 Claude Code 强多少?
论文报告在 6 个 AO 任务上,Arbor 都取得最佳 held-out 结果,平均相对 held-out gain 超过同接口同预算下 Codex 和 Claude Code 的 2.5 倍。
Arbor 为什么需要 held-out merge gate?
因为 dev set 上的提升可能只是过拟合探索反馈。只有当候选分支在 held-out evaluator 上也超过当前最好工件时,Arbor 才会接纳它。
Arbor 的主要局限是什么?
Arbor 依赖可执行任务、可靠评测器和可比较的 artifact 版本。对于依赖主观判断、多人协作或长延迟证据的科研场景,它还没有充分证明。
一句话:Arbor 的价值在于把自主科研改成证据管理问题,而不是单纯拉长智能体循环。阅读 arXiv 原文。