dMoE:扩散语言模型的块级专家路由
dMoE 让 MoE 路由对齐扩散 LLM 的块级并行解码:在 LLaDA2.0-mini 上把每块唯一专家从 69.5 降到 14.6,保留 99.11% 精度,专家显存省 76-80%。
快速答案
dMoE 通过按整块路由而非逐 token 路由,让混合专家(MoE)扩散语言模型变得便宜可跑。在开源 MoE 扩散模型 LLaDA2.0-mini 上,它把每个解码块唯一激活的专家数从 69.5 降到 14.6,同时保留原模型 99.11% 的精度,专家权重显存削减 76.64% 到 79.84%,端到端获得 1.14 倍到 1.66 倍加速。这不是堆更大的模型,而是一个观念上的修正:让”在哪里选专家”对齐扩散 LLM”实际怎么解码”。
dMoE 要解决的错配
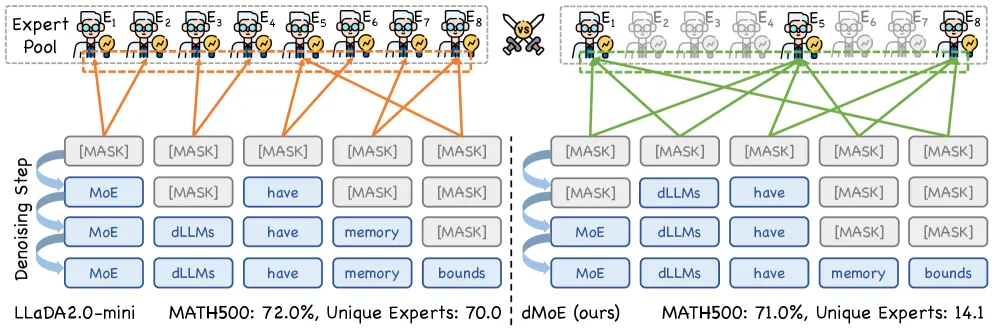
扩散语言模型不是从左到右逐字生成的,而是在若干去噪步里并行揭开一整块 token。但 MoE 路由沿用了自回归 transformer 的做法,仍按 token 选专家。当一块里的每个 token 都独立地挑自己的 top-k 专家时,整块触及的专家并集会爆炸。论文直接量化了这一点:LLaDA2.0-mini 上单个块平均激活 69.5 个不同专家,尽管每个 token 只用其中几个。这些专家全都得驻留显存供本块前向使用,于是块级并行解码把 MoE 本应带来的稀疏性变成了显存瓶颈。
核心观察就在这里:逐 token 路由和块级并行解码方向相反。token 路由追求每个 token 最大自由度;块解码则希望共享一个小工作集,让并行步保持便宜。
块级路由怎么做
dMoE 把块内各 token 的专家打分聚合成一个块级分布,再强制每个 token 只能从一个共享的专家核心集里选。
机制分四步。第一,照常算出块内每个 token 的路由分。第二,把所有 token 归一化后的分相加,形成单一的块级专家分布。第三,在该分布上做 top-p 选择,挑出累积路由质量超过阈值的专家核心集。第四,把每个 token 的最终选择限制在这个核心集内。token 仍各自路由,但只在整块认为重要的专家中挑。
“可学习”很关键:核心集来自模型自身学到的路由分,而非固定分配,因此高频专家得以保留,被个别 token 偶然选中的长尾专家被丢弃。论文还指出,扩散块内的 token 具有双向依赖、且被一起解码,本就应共享专家基底以保持连贯,因此这个核心集是特性而非单纯压缩技巧。
关键结果
- 激活专家:LLaDA2.0-mini 上每块唯一专家从 69.5 降到 14.6,约削减块级专家占用 79%。
- 精度保留:在所测基准上保留原模型 99.11% 的表现。
- 显存:专家显存削减 76.64% 到 79.84%,这是驻留专家集变小的直接收益。
- 延迟:端到端加速 1.14 倍到 1.66 倍,视运行点而定。
- 基准:在 MATH500、GSM8K、ARC-C 与 MMLU 数学子集上评测,对比 Top-4 专家上限以及 DES-S、DES-V 动态专家共享方法。
为什么现在重要
扩散 LLM 是当下对自回归解码最可信的挑战,而最强的开源版本(如 LLaDA2.0-mini)本身就是 MoE 模型。这意味着路由与解码的错配不是边角案例,它正处在开源语言建模中最有前景的架构组合的主干路径上。dMoE 表明这个错配可以在路由层修复,无需重训稠密模型、也无需缩小专家池,这正是让 MoE 扩散 LLM 能在更紧显存预算上部署的关键。
局限与存疑
论文明确标注为进行中(work-in-progress),评测面较窄。所有数字都来自单一基座 LLaDA2.0-mini,因此 14.6 的专家核心集与显存收益能否在更大的 MoE 扩散模型或不同专家数上成立尚未验证。基准偏向推理与知识(MATH500、GSM8K、ARC-C、MMLU 数学),不含开放式生成、代码或长上下文任务,而这些场景下的块内连贯压力可能不同。99.11% 的保留率是平均值,现有材料未拆分哪些基准损失最大,top-p 核心集阈值这一旋钮的敏感度也未充分刻画。
常见问题
dMoE 解决什么问题?
dMoE 修复扩散 LLM 块级并行解码与逐 token MoE 路由的冲突。当并行解码块里每个 token 独立选专家时,LLaDA2.0-mini 上整块平均触及 69.5 个不同专家,全都得驻留显存。dMoE 通过让整块共享一个专家核心集,把这个数字压到 14.6。
dMoE 能省多少显存?
dMoE 在 LLaDA2.0-mini 上把专家权重显存削减 76.64% 到 79.84%,端到端延迟加速 1.14 倍到 1.66 倍,因为每个并行解码步需要驻留的专家少了很多。
dMoE 会损害精度吗?
dMoE 在 MATH500、GSM8K、ARC-C 与 MMLU 数学子集上保留 LLaDA2.0-mini 原始精度的 99.11%。这点小幅下降源于强制块内每个 token 在共享专家核心集内路由,而非自由选择。
dMoE 跑在什么模型上?
dMoE 在 LLaDA2.0-mini 上验证,这是一个开源混合专家扩散语言模型。论文标注为进行中,仅在该单一基座上报告结果,对其他 MoE 扩散 LLM 的泛化尚未展示。