MemPrivacy:用可逆占位符守住端云 Agent 的记忆隐私
MemPrivacy 端侧把敏感片段换成带类型占位符交云端处理记忆,再本地还原,效用损失控制在 1.6% 内,0.6B-4B 小模型识别隐私片段反超 GPT-5.2。
快速答案
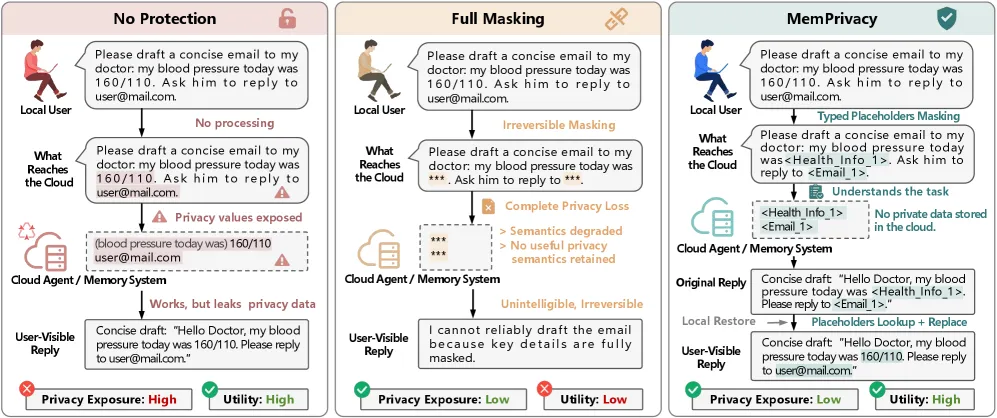
MemPrivacy 让云端 Agent 能建立长期个性化记忆,却始终看不到你的原始隐私:端侧小模型先识别敏感片段,换成带语义类型的占位符,云端只在占位符上推理,设备在呈现给你之前再本地还原真实值。在 LangMem、Mem0、Memobase 三套生产级记忆系统上,这种可逆假名化把任务效用损失压在 1.6% 以内,而不可逆掩码会损失 16.99-41.87%。团队专门训练的 0.6B-4B 模型在自建的 MemPrivacy-Bench 上拿到 85.97% F1、在 PersonaMem-v2 上达 94.48%,在同一识别任务上击败了 GPT-5.2 和 Gemini-3.1-Pro。
Agent 记忆的隐私缺口
个性化 Agent 只有记住你才有用——你的用药、薪资、住址、API 密钥——而这份记忆越来越多地存在跑着大模型的云端。最朴素的隐私做法是掩码:数据离开设备前把敏感处涂黑。但掩码有损且不可逆。一旦「降压药让我头晕」变成「[已删除]让我[已删除]」,云端就无法再对医疗语境推理,你也永远拿不回原文。MemPrivacy 的判断是:真正需要的不是删除,而是可逆 + 类型信息——云端需要知道它在处理的是一种药物、一个人还是一个地点才能正确推理,但并不需要里面的具体值。
可逆管线如何运作
方法是三阶段的本地可逆假名化。第一步,端侧检测器找出隐私片段,把每个换成携带语义类型的占位符——药名换成带类型的药物占位符,而非一个通用空白。第二步,云端 Agent 及其记忆系统完全在占位符文本上运作,明文隐私从不离开设备。第三步,设备保存映射关系,在把结果呈现给用户前本地还原真实值。保留类型正是效用得以保住的关键:云端仍知道句子结构,只是不知道其中的身份。
敏感度用四级分类法划定。PL1 是通用偏好(视为非敏感、排除在外);PL2 是直接或间接的身份识别信息;PL3 是基于伤害的数据,如健康、财务、生物特征;PL4 是可立即被利用的凭证,如密码、令牌、密钥。这让保护力度可调:全量保护 PL2-PL4 会多损一点效用,而只保护 PL4 几乎是免费的。
MemPrivacy-Bench 里有什么
作者自建 MemPrivacy-Bench,是因为现有基准都没覆盖分级、可逆的记忆隐私。它涵盖 200 名用户、超过 52,000 条隐私实例,约 100 万对话 token,中英文各占一半。训练集为 160 名用户的 26,016 轮(12.5 万+ 隐私实例),测试集为 40 名用户的 6,337 轮(2.99 万实例)。人工核验后标注准确率达 98.08%。在此之上,他们用监督微调加 GRPO 强化学习(以 F1 为奖励信号)训练了六个 0.6B 到 4B 参数的 MemPrivacy 检测模型。
关键结果
- 效用损失在 1.6% 以内。 全量保护 PL2-PL4 在 LangMem、Mem0、Memobase 上花费 0.71-1.60% 的任务效用;只保护 PL4 仅花费 0.08-0.33%。
- 可逆远胜掩码。 不可逆掩码在同样系统上损失 16.99-41.87%,无类型占位符也要损 4.72-8.71%——类型信息在实打实地起作用。
- 专用小模型在识别上反超前沿大模型。 在 MemPrivacy-Bench 上最佳 MemPrivacy 模型达 85.97% F1,比 GPT-5.2 高 16.98%、比 Gemini-3.1-Pro 高 7.56%;在 PersonaMem-v2 上达 94.48% F1(对 GPT-5.2 +6.42%,对 Gemini-3.1-Pro +7.89%)。
- 一个对照的弱基线。 OpenAI-Privacy-Filter 基线在 MemPrivacy-Bench 上只有 35.50% F1,说明现成过滤器远不达标。
- 延迟很低。 端侧检测器在 MemPrivacy-Bench 上约 2 秒、在 PersonaMem-v2 上低于 1 秒。
为什么 0.6B 模型胜出值得关注
这里最有价值的结论不是那个 F1 头条数字,而是:一个为单一窄任务(带类型的隐私片段识别)微调的 0.6B-4B 模型,能在该任务上击败 GPT-5.2 和 Gemini-3.1-Pro。这正是端侧部署所需要的形态:隐私关键步骤必须本地跑,而手机上塞不下一个前沿模型。MemPrivacy 证明小专家就能过线,让整套端云分工从愿景变成可落地。可逆的视角也是对「掩码反射」的正确纠偏——对 Agent 记忆来说你几乎总要在之后取回原值,所以销毁它从来就是个错误的默认。
局限与存疑
隐私保证的强度只等于检测器的召回:任何端侧模型没标成敏感的内容,都会以明文离开设备,而 85.97% 的 F1 意味着在困难或新型敏感片段上确有漏检。该基准是作者自建、人工标注到 98.08% 准确率,因此对 GPT-5.2、Gemini-3.1-Pro 的对比数字尚未经第三方复现。带类型的占位符能减少但不能消除泄露——云端仍会得知你隐私数据的结构和类型,这本身就可能有信息量。其威胁模型假设云端是「诚实但好奇」的,并不防御主动用辅助信息反推占位符的云端。低于 1.6% 的效用数字能否在这三个记忆库之外、更复杂的多轮 Agent 任务上成立,仍然存疑。
常见问题
MemPrivacy 解决什么问题?
它让端云 Agent 能保留对用户有用的长期记忆,却不把原始敏感数据送上云端。设备把隐私假名化成带类型的占位符,云端在占位符上推理,设备再本地还原真实值。
MemPrivacy 和直接掩码敏感数据有什么不同?
掩码是不可逆的、丢掉了语义类型,在测试的记忆系统上要损 16.99-41.87% 效用。MemPrivacy 用可逆、带类型的占位符,让云端仍理解句子结构、用户也能取回原值,把效用损失控制在 1.6% 以内。
MemPrivacy 真的击败了 GPT-5.2 和 Gemini-3.1-Pro 吗?
在隐私片段识别上是的。它的 0.6B-4B 模型在 MemPrivacy-Bench 上达 85.97% F1(比 GPT-5.2 高 16.98%、比 Gemini-3.1-Pro 高 7.56%),在 PersonaMem-v2 上达 94.48%。这是一项窄的专用任务,不是通用能力。
MemPrivacy-Bench 是什么?
一个含 200 名用户、52,000+ 隐私实例、约 100 万中英双语对话 token 的基准,采用 PL1-PL4 四级敏感度分类,人工核验标注准确率 98.08%。
MemPrivacy 用来保护凭证可靠吗?
只保护 PL4 凭证(密码、令牌、密钥)仅花费 0.08-0.33% 效用,因此开启成本很低。但保护取决于检测器召回——本地模型漏掉的任何凭证仍会离开设备,所以它该是一层,而非唯一一层。
一句话:别删除隐私,把它在本地连同类型一起假名化,之后再放回去。阅读 arXiv 原文。