自蒸馏智能体强化学习:特权教师逐 token 引导 GRPO
SDAR 在 GRPO 之上加了一路带门控的 token 级自蒸馏信号,由「看得到检索技能」的教师引导,让多轮智能体在 WebShop 上最高 +10.2、ALFWorld 上 +9.4。
快速答案
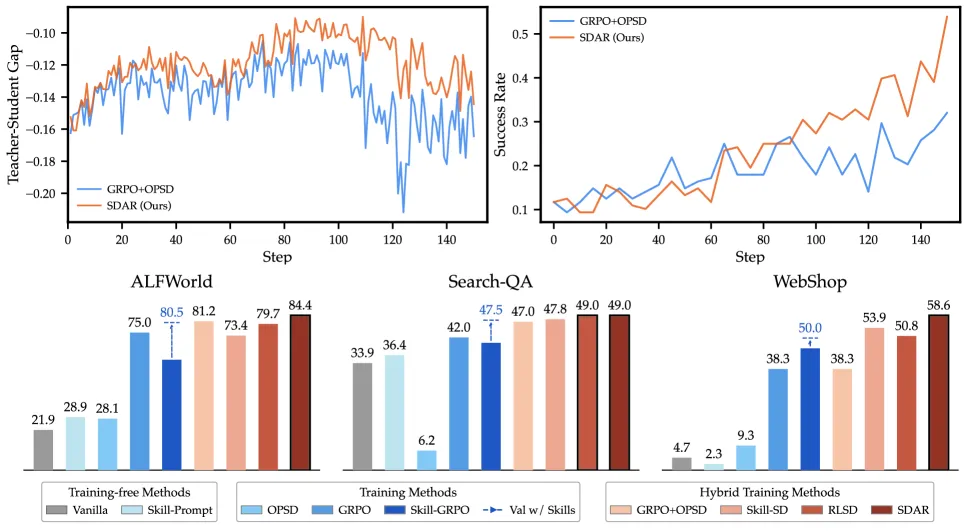
SDAR(自蒸馏智能体强化学习)给普通 GRPO 接上一路稠密的 token 级自蒸馏信号,让多轮智能体在每个 token 上都拿到梯度,而不只是回合结束时一个稀疏奖励。一个「能看到检索出的技能」的特权教师引导学生策略,再用一个 sigmoid 门控逐 token 决定信几分。在 Qwen2.5-3B-Instruct 上,它把 ALFWorld 从 75.0% 提到 84.4%(+9.4),Search-QA 从 36.4% 提到 43.4%(+7.0),WebShop 准确率从 63.3% 提到 68.0%;单项最大涨幅是 Qwen3-1.7B 在 WebShop 上的 +20.3。
智能体 RL 的稀疏奖励难题
用 GRPO 训一个 LLM 智能体去做家务任务(ALFWorld)、多跳搜索(Search-QA)或网购(WebShop),会撞上一个残酷的信用分配问题:奖励只在长长的多轮轨迹末尾才出现,模型拿一个标量去解释几十个 token 级决策。纯结果奖励的 RL 恰恰在这种场景下既耗样本又不稳。最直接的解法——向更强的教师蒸馏——通常意味着再要一个更强的模型,既贵又往往拿不到。
SDAR 怎么做
SDAR 的教师不是更大的模型,而是同一个策略外加特权上下文:从过往经验里检索出的相关技能,而学生在推理时看不到这些技能。因为教师只多了点上下文,它逐 token 的对数概率就成了一个廉价、同策略的蒸馏目标。论文把这套叫在策略自蒸馏(OPSD),它作为辅助损失加进来:L = L_GRPO + λ · L_SDAR,RL 仍是主目标,蒸馏只是被门控的帮手,而非替代。
关键的工程动作是 token 级门控。作者发现,朴素自蒸馏在多轮场景会崩,原因有二:教师与学生的偏移会随轮次累积;而且因为技能检索并不完美,超过 50% 的 token 其实呈现负的师生对数概率差——也就是说教师在那里反而更差。于是一个作用在差值 Δₜ 上的 sigmoid 门控对 token 区别对待:正差 token(教师确实更强)加大蒸馏,负差 token 则被柔性衰减。这正是 SDAR 与「直接把 KL-to-teacher 硬塞进 GRPO」的区别。
关键结果
以下均为成功率 / 准确率,SDAR 对比 GRPO 基线:
- Qwen2.5-3B-Instruct: ALFWorld 75.0% → 84.4%(+9.4),Search-QA 36.4% → 43.4%(+7.0),WebShop-Acc 63.3% → 68.0%(+4.7)。
- Qwen2.5-7B-Instruct: ALFWorld 81.2% → 85.9%(+4.7),Search-QA 42.0% → 49.0%(+7.0),WebShop-Acc 72.6% → 82.8%(+10.2)。
- Qwen3-1.7B-Instruct: ALFWorld 46.1% → 53.9%(+7.8),Search-QA 40.8% → 41.9%(+1.1),WebShop-Acc 38.3% → 58.6%(+20.3)。
- 对检索质量稳健: ALFWorld 的增益在各档检索下都在——UCB +5.6、关键词匹配 +4.7,连随机检索都有 +1.9——说明真正起作用的是门控,而不是完美的技能。
一句实话:增益真实且一致,但并不均匀。Search-QA 涨得最少(Qwen3-1.7B 仅 +1.1),而那个亮眼的 +20.3 来自小模型在一个基线本就很弱(38.3%)的任务上。方法在「空间最大」的地方帮得最多。
门控才是真正的贡献
这里有意思的主张不是「蒸馏能帮 RL」——那是老话。而是在多轮智能体 RL 里,不加门控的教师信号反而有害,因为教师在多数 token 上并不可靠。SDAR 用「过半 token 呈负差」这个统计来佐证非对称门控的合理性;而随机检索消融(技能纯噪声时仍 +1.9)说明门控是在抢救一个弱信号,而非依赖一个强信号。这把自蒸馏从「抄一个更强的模型」重新框定为「有选择地信任一个偶尔更懂的同尺寸模型」。
局限与存疑
教师在训练时需要特权技能;论文称策略已把这些内化、推理时无依赖,但这个「内化」更多是断言,而非压力测试过的结论。超参敏感:报告的甜点位(β=5.0、λ=0.01)需要调,且门控激活率在训练早期一直低于 50%,意味着部分蒸馏信号被浪费。所有评测都在不超过 7B 的 Qwen2.5/Qwen3 上、只用三个基准——没有大规模模型,没有编码或工具调用类智能体,也没有与一个真正更强的外部教师对比。当真有更大模型可用时,这套「同模型教师」的把戏能否胜过直接向大模型蒸馏,论文留白。
常见问题
什么是自蒸馏智能体强化学习(SDAR)?
SDAR 是一种训练方法,在 GRPO 之上为多轮 LLM 智能体加了一路在策略自蒸馏损失。教师就是「被喂入检索技能作为特权上下文」的同一个策略,提供稠密的 token 级引导,并按师生对数概率差逐 token 门控。
SDAR 相比 GRPO 能提升多少?
在 Qwen2.5-3B-Instruct 上,SDAR 在 ALFWorld 上 +9.4、Search-QA 上 +7.0、WebShop 准确率 +4.7;在 Qwen2.5-7B 上 WebShop +10.2;单项最大增益是 Qwen3-1.7B 在 WebShop 上的 +20.3。
SDAR 为什么要用 token 级门控?
因为在多轮场景下,超过 50% 的 token 呈负的师生差——由于技能检索不完美,教师在那里反而更差。sigmoid 门控只在教师确实更强处放大蒸馏,其余处衰减。
SDAR 需要一个更大的教师模型吗?
不需要。教师是被喂入检索技能的同一个模型,蒸馏目标既廉价又同策略。即便随机检索也仍有增益(ALFWorld +1.9),说明驱动提升的是门控,而非更强的教师。
一句话:让 GRPO 当家,加上一个同尺寸教师的 token 级建议,再用门控保证只在教师确实对的地方去抄它。阅读 arXiv 原文。