Skill1:一个 RL 策略统一管技能的选、用、蒸
Skill1 用一个 Qwen2.5-7B 策略,在同一任务结果奖励下统一学会检索、使用、提炼可复用技能,ALFWorld 达 97.5%,超最强纯 RL 基线 6.5 个点。
快速答案
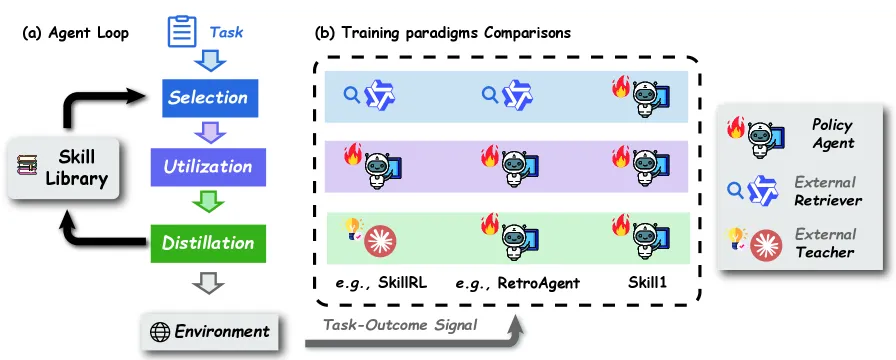
Skill1 用一个强化学习策略,同时干三件以往被分开优化的事:从技能库里检索相关技能、在解题时应用它们、再从成功轨迹里提炼出新技能。三者都由同一个任务结果奖励、通过 GRPO 驱动。在 ALFWorld 上这个统一策略拿到 97.5% 的平均成功率,比最强的纯 RL 基线 GiGPO(90.8%)高出 6.5 个点;在 WebShop 上得分 89.7、成功率 82.9%——全部跑在单个 Qwen2.5-7B-Instruct 基座上。
「技能增强」智能体为什么总坏掉
技能库的吸引力很直白:解过一次的任务,智能体不该从头再学一遍。问题在于,对这个库的三种操作——挑对技能、用好技能、写出好的新技能——一直是各自孤立地训练或手工硬编码。一个按嵌入相似度调好的检索器,根本不知道它捞出来的技能对下游策略到底有没有帮助;一个只会总结轨迹的蒸馏步骤,也得不到「这条新技能后来有没有被成功复用」的反馈。Skill1 的论点是:这种割裂本身就是 bug——每个组件都在优化一个代理目标,而这些代理目标拼不出好的端到端行为。
统一策略怎么工作
Skill1 把选择、使用、蒸馏揉进一个策略,全部挂到同一个信号上——任务成没成功。具体地,智能体跑一个循环:拿到任务先检索候选技能,策略以这些技能为条件在环境中行动,回合结束后再把新技能蒸馏回库里。训练用 GRPO(组相对策略优化),每个任务 16 条 rollout 一组,学习率 1e-6,技能嵌入用冻结的 all-MiniLM-L6-v2 编码器(384 维)。两个权重各 0.3 的辅助损失分别约束选择与蒸馏;技能效用用指数滑动平均(系数 0.05)追踪,好让库能裁掉从不见效的技能,上限 5000 条。
诚实地说,它的新意不在新的 RL 算法——GRPO 是从推理模型那边借来的。真正的贡献是信用分配的设计:把一个结果奖励同时传给三种技能操作,让它们协同适应,而不是互相打架。
关键结果
- ALFWorld 平均成功率 97.5%,各类别为:Pick 100.0%、Look 98.6%、Clean 97.3%、Heat 99.2%、Cool 96.1%、Pick2 96.0%。
- 比 GiGPO 高 6.5 个点,后者是最强纯 RL 基线(90.8%);也领先 RetroAgent(94.9%)和 SkillRL(89.9%)。
- WebShop 得分 89.7、成功率 82.9%,说明方法能从具身家务任务迁移到网页导航。
- 消融证明每个部件都在出力。 去掉技能库,ALFWorld 从 97.5% 掉到 80.9%(−16.6);去掉选择损失 5.7 个点(91.8%);去掉蒸馏损失 5.1 个点(92.4%)。把选择辅助损失置零(lambda1=0)得 94.0%,把蒸馏损失置零(lambda2=0)得 94.9%。
- 成本不高: 训练在 100-150 步内收敛,ALFWorld 上约 8 张 NVIDIA H800-80GB GPU 跑 30 小时。
最扎眼的单个数字是技能库消融:去掉库就掉 16.6 个点,说明大部分收益来自技能的积累与复用,而不是 RL 调优本身。
为什么现在重要
2026 年的智能体研究正在收敛到一个共识:经验应当复利——智能体见某一类任务越多,就该越擅长。Skill1 是个干净的证据:要让技能库真的产生复利,得把它的各项操作放在真实目标下联合训练,而不是把一个冻结的检索器硬接到一个冻结的策略上。这个教训能推广到这两个基准之外,哪怕具体数字未必能。
局限与存疑
评测面很窄。ALFWorld 和 WebShop 都是被反复刷过、结构相对清晰、成功信号明确的环境——恰恰是结果奖励 RL 最吃得开的场景。同样的协同进化能否帮到开放式、稀疏奖励或长程的真实世界任务,这里没验证。基座只有一个 7B 模型,所以统一策略的优势如何随模型规模变化、换个更强基座会不会把简单基线的差距抹平,都不清楚。5000 条上限加 EMA 裁剪是合理的工程手段,却缺乏原理性分析——库饱和或技能冲突时会怎样,没有交代。而且和多数结果奖励方法一样,它依赖一个可判定的奖励,而大多数杂乱的真实任务并不提供。
常见问题
Skill1 是什么,解决什么问题?
Skill1 是一个强化学习框架,训练单个策略为语言模型智能体检索、应用并创建可复用技能。它解决的是:这三种操作各自孤立优化时,拼不出好的端到端行为这一失效模式。
Skill1 和检索增强智能体有什么不同?
检索增强智能体用一个按嵌入相似度打分的固定检索器。Skill1 把选择、使用、技能蒸馏放在同一个任务结果奖励下联合训练,所以检索器学到的是「真正帮到策略」的东西,而不是「看起来相似」的东西。
Skill1 报告了哪些基准,结果有多强?
ALFWorld 上 Skill1 平均成功率 97.5%,比最强纯 RL 基线 GiGPO(90.8%)高 6.5 个点。WebShop 上得分 89.7、成功率 82.9%,均使用 Qwen2.5-7B-Instruct 基座。
Skill1 提出了新的 RL 算法吗?
没有。Skill1 用的是 GRPO,即推理模型训练中常见的组相对策略优化。它的贡献是把一个结果奖励路由到全部三种技能操作的信用分配设计。
Skill1 的主要局限是什么?
它只在两个结构化基准(ALFWorld 与 WebShop)、单个 7B 模型上测试,且依赖可判定的任务结果奖励。它在更大规模、开放式任务以及技能库饱和时的表现,仍未被探索。
一句话:把技能的选、用、蒸都挂到同一个结果奖励上,一个 7B 智能体的技能库才真正产生复利。阅读 arXiv 原文。