Token 可教性:只监督 5% token 蒸馏大模型
TA-OPD 只监督教师修正落在学生 top-K 支撑集内的约 5% token,效果常追平甚至超过全 token 在线蒸馏(Qwen3-4B 蒸 1.7B:44.89 对 42.37)。
快速答案
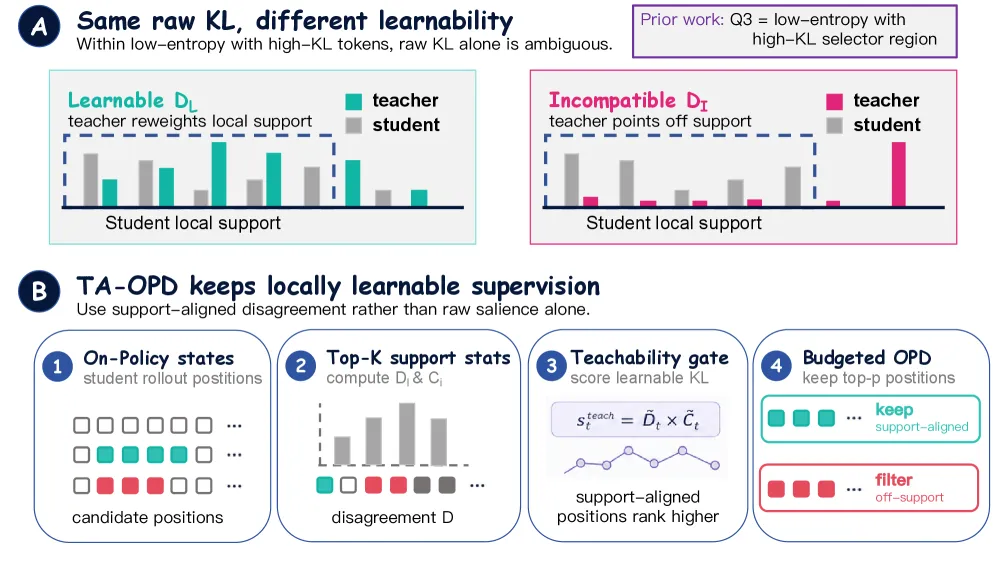
在线蒸馏(OPD)让学生模型在自己的 rollout 上训练,教师对每个 token 打分,标准目标是在全部 token 上最小化 KL 散度。这篇论文的判断更尖锐:大部分 token 级别的分歧其实是无用功,因为教师在把概率质量推向学生当前根本够不到的 token。
作者把分歧拆成两块。可学习分歧是落在学生自己 top-K 候选集内的教师质量,这种修正学生一步梯度就能吸收。不兼容分歧是落在学生支撑集之外的教师质量:KL 数字很大,却给不出可用的信号。他们的选择方法 TA-OPD(可教性感知在线蒸馏) 按可教性分数给 token 排序,只监督最高的一小片。保留约 5% token 时,效果常常追平甚至超过监督全部 token。
如果你在 Qwen 系列上跑推理蒸馏管线,这篇值得一读。但如果你想要一个即插即用的训练加速器,请先降低预期:它削减的是「哪些 token 被监督」,而不是前向计算量(下面细说)。
Token 可教性是怎么定义的
核心概念是兼容质量(compatibility mass):在某个位置上,教师概率中落在学生 top-K 候选集里的比例。兼容质量高,说明教师偏好的下一个 token 本就是学生认为合理的,梯度只是把已有的峰值往上推,而不是去追一个遥远的模式。
每个 token 的可教性分数,本质上是归一化的局部分歧乘以归一化的兼容质量,并用 5th-95th 分位区间做批内稳健归一化,把值裁剪到 [0,1]。把 top-K 并集上的局部分歧做分解,就得到一个可学习分量(分歧按兼容质量加权)和一个不兼容分量(按其补集加权)。原始 KL 把两者混在一起,而可教性把真正能推动学生的那部分单独拎出来。
为了验证这个区分是因果而非花架子,作者设计了固定上下文诊断:冻结一段学生生成的前缀,再在这段完全相同的上下文上测量训练前后的 KL 下降。冻结上下文消除了 rollout 方差,因此测到的增益可以归因于 token 级别的学习。在多组 Qwen3 配对上,支撑对齐的(可学习)token 都显示出稳定的正增益优势。例如 Qwen3-4B 蒸 1.7B 在 GSM8K-COT 思维链上下文上为 +0.087 [+0.066, +0.109],Qwen3-8B 蒸 1.7B 为 +0.118 [+0.094, +0.144]。在 K = 8、16、32 上做回归,可学习分歧的系数(约 0.086)大约是不兼容分歧(约 0.044)的两倍,自助法差距约 +0.04。
关键结果
- 平均 44.89 对 42.37(+2.52):Qwen3-4B 蒸 Qwen3-1.7B,10% 监督 token 预算下,TA-OPD 在六个基准(AIME24/25、GPQA-Diamond、HumanEval、IFEval、MATH-500)上对全 token OPD 的提升。
- 56.87 对 53.71(+3.16):Qwen3-8B-GRPO 蒸 Qwen3-4B;54.65 对 54.64:Qwen3-14B 蒸 Qwen3-4B(基本打平);30.62 对 28.76(+1.86):跨骨干的 DeepSeek-R1-Distill-Qwen-14B 蒸 Qwen2.5-3B。
- 压过显而易见的基线。 Qwen3-4B 蒸 1.7B、10% 预算下,TA-OPD 的 44.89 高于纯熵选择(41.46)和 TIP(熵加散度规则,43.05)。有意思的是,混入熵的 TA-OPD+Entropy 反而掉到 42.32,可教性信号越纯越好。
- 5% 就可能够用。 Qwen3-8B-GRPO 蒸 Qwen3-4B 时,5% 预算拿到 57.35,反而压过了 10%、30%、50% 预算,说明 token 质量可以胜过 token 数量。
- 选择器本身很关键。 Qwen3-8B-GRPO 上的下游消融显示,原始 KL 选择为 53.76、纯兼容质量为 54.19,都低于 TA-OPD 的 54.65,证明增益来自分歧与兼容质量的结合,而非任一单项。
为什么现在重要
OPD 已经成了压缩推理模型的默认配方,而领域里大多把「监督每个 token、最小化 KL」当成稳妥选择。这篇论文是一个有用的纠偏:它表明 KL 信号里有很大一部分是学生根本无法响应的噪声,而一个廉价的诊断就能找出真正要紧的 token。「质量胜过数量」这个朴实的提法之所以比又一个采样启发式更站得住脚,是因为它配了一个因果探针(固定上下文增益),而不只是一个端到端任务的差值。
真正有意思的结果是 5% 预算有时直接胜出。这暗示教师的完整分布在不兼容 token 上不仅冗余,甚至略有害:它把学生往自己表示不了的模式上拽。这比「我们省了标注」是更强的论断,也是后续工作最值得审视的地方。
局限与存疑
- 没有真正的墙钟加速。 这是标题藏起来的关键前提。TA-OPD 选的是哪些位置被监督,并不裁剪前向计算。教师和学生仍然要跑完整个序列,所以「5% token 预算」是监督预算,不是 20 倍训练提速。指望靠它做廉价蒸馏加速器的人可以直接跳过。
- 评测面太窄。 几乎全是 Qwen 系列上的数学推理,跨骨干只有 DeepSeek 蒸 Qwen2.5 这一个点,作者自己也承认。多语言、对话、代码专用教师都没测,而 Qwen3-14B 那一档已经显示增益可能塌到零。
- 大 K、大预算时优势很小。 Qwen3-14B 打平,加上预算敏感性表里 TIP 在 30% 处反超,说明优势真实但并非处处稳健。师生差距适中时优势最大。
- 诊断是局部的。 固定上下文 KL 下降解释的是单步可学习性,而非整条轨迹的质量;作者也正确地提醒,在做部署结论前应配合下游评测。
常见问题
TA-OPD 里「可学习分歧」和「不兼容分歧」有什么区别?
可学习分歧是落在学生 top-K 候选集内的教师概率质量,学生能在本地吸收这种修正;不兼容分歧是落在支撑集之外的教师质量,它抬高了 KL 散度,却给不出可用梯度。TA-OPD 的可教性分数用兼容质量给原始分歧加权,只保留可学习的那部分。
Token 可教性(TA-OPD)真的能加快蒸馏训练吗?
不能,这是它最大的局限。TA-OPD 降低的是监督 token 预算(约 5-10%),而不是前向计算量。教师和学生仍要处理完整序列,所以论文里的预算是监督预算,并非按比例的训练提速。
TA-OPD 这篇论文测了哪些模型,提升有多大?
主要是 Qwen3 师生配对,外加一个 DeepSeek 蒸 Qwen2.5 的跨骨干例子。10% 预算下,相对全 token OPD 的提升从 +3.16(Qwen3-8B-GRPO 蒸 Qwen3-4B)到基本为零(Qwen3-14B 蒸 Qwen3-4B 仅 +0.01)不等,所以收益真实但不均匀。