Fine-Tuning & Adaptation · LLM Reasoning · Efficient AI
Token Teachability: Distilling LLMs on Just 5% of Tokens
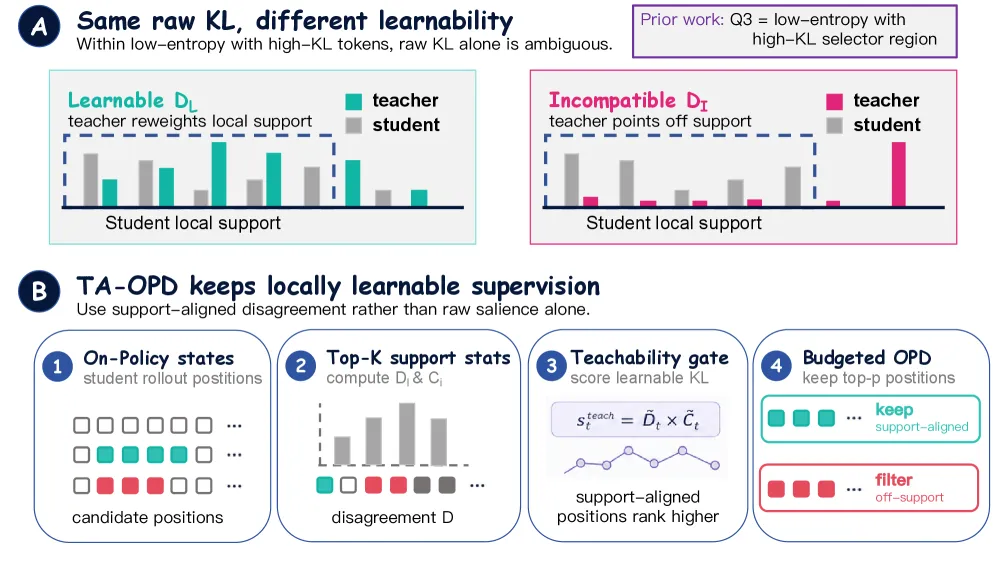
Teachability-Aware OPD supervises only ~5% of tokens, those where the teacher's correction lands inside the student's top-K support, matching or beating full-token distillation (44.89 vs 42.37 on Qwen3-4B to 1.7B).
Quick answer
On-policy distillation (OPD) trains a student LLM on its own rollouts while a teacher scores every token. The standard objective minimizes KL divergence on all of them. This paper’s claim is sharper: most of that token-level disagreement is wasted effort, because the teacher is pushing probability mass toward tokens the student cannot reach right now.
The authors split disagreement into two parts. Learnable disagreement is teacher mass that lands inside the student’s own top-K candidates, a correction the student can absorb in one gradient step. Incompatible disagreement is teacher mass sitting outside the student’s support: a large KL number that produces little usable signal. Their selection method, Teachability-Aware OPD (TA-OPD), ranks tokens by a teachability score and supervises only the top slice. With about 5% of tokens kept, it often matches or beats supervising all of them.
If you run reasoning distillation pipelines on Qwen-family models, this is worth a read. If you want a drop-in training speedup, temper expectations: it cuts which tokens get supervised, not how much compute the forward pass burns. More on that below.
How token teachability is defined
The core construct is compatibility mass: the share of the teacher’s probability that falls on the student’s top-K candidate set at a given position. High compatibility means the teacher’s preferred next tokens are ones the student already considers plausible, so the gradient nudges an existing peak rather than chasing a far-away mode.
The teachability score per token is essentially normalized local disagreement multiplied by normalized compatibility, with batch-wise robust normalization clipping values to [0,1] using a 5th-95th percentile range. Decomposing the local disagreement on the union of top-K sets gives a learnable component (disagreement weighted by compatibility) and an incompatible component (disagreement weighted by its complement). Raw KL conflates the two. Teachability isolates the part that actually moves the student.
To test whether this distinction is causal rather than cosmetic, the authors use a fixed-context diagnostic: freeze a student-generated prefix, then measure the KL reduction on that identical context before and after training. Freezing the context removes rollout variance, so any measured gain is attributable to token-level learning. Across Qwen3 pairs, support-aligned (learnable) tokens show a consistent positive gain advantage. For example, +0.087 [+0.066, +0.109] on GSM8K-COT chain-of-thought contexts for Qwen3-4B to Qwen3-1.7B, and +0.118 [+0.094, +0.144] for Qwen3-8B to Qwen3-1.7B. A regression across K = 8, 16, 32 finds the learnable-disagreement coefficient (around 0.086) roughly double the incompatible one (around 0.044), with a bootstrap gap of about +0.04.
Key results
- 44.89 vs 42.37 average (+2.52) for Qwen3-4B to Qwen3-1.7B at a 10% supervised-token budget: TA-OPD over full-token OPD across six benchmarks (AIME24/25, GPQA-Diamond, HumanEval, IFEval, MATH-500).
- 56.87 vs 53.71 (+3.16) for Qwen3-8B-GRPO to Qwen3-4B; 54.65 vs 54.64 for Qwen3-14B to Qwen3-4B (a dead heat); 30.62 vs 28.76 (+1.86) for the cross-backbone DeepSeek-R1-Distill-Qwen-14B to Qwen2.5-3B setting.
- Beats the obvious baselines. On Qwen3-4B to Qwen3-1.7B at 10%, TA-OPD’s 44.89 tops entropy-only selection (41.46) and TIP, an entropy-plus-divergence rule (43.05). Curiously, mixing in entropy (TA-OPD+Entropy) drops it to 42.32; the teachability signal works best clean.
- 5% can be enough. On Qwen3-8B-GRPO to Qwen3-4B, the 5% budget scores 57.35, edging out the 10%, 30%, and 50% budgets. Token quality can outweigh token count.
- The selector matters. A downstream ablation on Qwen3-8B-GRPO shows raw KL selection at 53.76 and compatibility-only at 54.19, both below TA-OPD’s 54.65, confirming the gain comes from combining disagreement and compatibility, not either alone.
Why this matters now
OPD has become a default recipe for shrinking reasoning models, and the field has mostly treated “supervise every token, minimize KL” as the safe choice. This paper is a useful corrective: it shows that a large fraction of the KL signal is noise the student cannot act on, and that a cheap diagnostic can find the tokens that matter. The honest framing of token quality over token count is more defensible than yet another sampling heuristic, because it comes with a causal probe (the fixed-context gain) rather than just an end-task delta.
The genuinely interesting result is the 5% budget sometimes winning outright. That hints the teacher’s full distribution is not just redundant but mildly harmful on incompatible tokens, dragging the student toward modes it cannot represent. That is a stronger claim than “we save labels,” and it is the part worth scrutinizing in follow-up work.
Limits and open questions
- No wall-clock speedup. This is the load-bearing caveat the title hides. TA-OPD selects which positions get supervised; it does not prune the forward pass. The teacher and student still run over the full sequence, so a “5% token budget” is a supervision budget, not a 20x training speedup. Anyone hoping for a cheap distillation accelerator should skip it.
- Narrow evaluation surface. Almost everything is math-heavy reasoning on Qwen-family pairs, with a single cross-backbone point (DeepSeek-to-Qwen2.5). The authors say so themselves. Multilingual data, dialogue, and code-specialized teachers are untested, and the Qwen3-14B case already shows the margin can collapse to zero.
- Margins are small at large K and large budgets. The Qwen3-14B tie and the mixed budget-sensitivity table (TIP wins at 30%) suggest the advantage is real but does not hold everywhere; it is largest when the teacher-student gap is moderate.
- The diagnostic is local. Fixed-context KL reduction explains one-step learnability, not full trajectory quality; the authors correctly flag that it should be paired with downstream evaluation before deployment claims.
FAQ
What is the difference between learnable and incompatible disagreement in TA-OPD?
Learnable disagreement is teacher probability mass that falls inside the student’s top-K candidates, so the student can absorb the correction locally. Incompatible disagreement is teacher mass outside that support; it inflates KL divergence but yields little usable gradient. TA-OPD’s teachability score weights raw disagreement by this compatibility, keeping only the learnable part.
Does Token Teachability (TA-OPD) actually speed up distillation training?
No, and this is its biggest limitation. TA-OPD reduces the supervised-token budget (to roughly 5-10%), not the compute of the forward pass. Both teacher and student still process the full sequence, so the reported budgets are supervision budgets, not proportional training speedups.
Which models did the TA-OPD paper test, and how big were the gains?
Mostly Qwen3 teacher-student pairs plus one DeepSeek-to-Qwen2.5 cross-backbone case. At a 10% budget, gains over full-token OPD ranged from +3.16 (Qwen3-8B-GRPO to Qwen3-4B) down to essentially zero (+0.01 for Qwen3-14B to Qwen3-4B), so the benefit is real but uneven.