LatentSkill:把智能体技能烧进 LoRA 权重,而非塞进提示词
超网络一次前向就把文本技能编译成 LoRA。ALFWorld 成功率涨 21.4 分,prefill token 省 64.1%。
快速答案
LatentSkill 把 LLM 智能体的技能库从提示词里搬进模型权重。一个预训练好的 Transformer「技能编译器」G_φ 读入一份文本技能文档,单次前向就吐出一组 LoRA 适配器;这组适配器在智能体执行时挂载上去,于是运行时该技能几乎不占用上下文 token。在 ALFWorld 上,它把任务成功率在 seen 划分上拉高 21.4 分(74.3% 对比 in-context 基线的 52.9%),unseen 划分上拉高 13.4 分(69.4% 对比 56.0%),同时 prefill token 少用 64.1%。在 Search-QA 上,精确匹配涨 3.0 分,技能 token 开销砍掉 72.2%。
真正的看点不是「LoRA 打败提示词」,而是:你可以按需从文本生成一个能用的适配器,不必为每个技能单独训练;而且生成出来的权重空间技能,表现得像可组合的对象。
技能编译器怎么工作
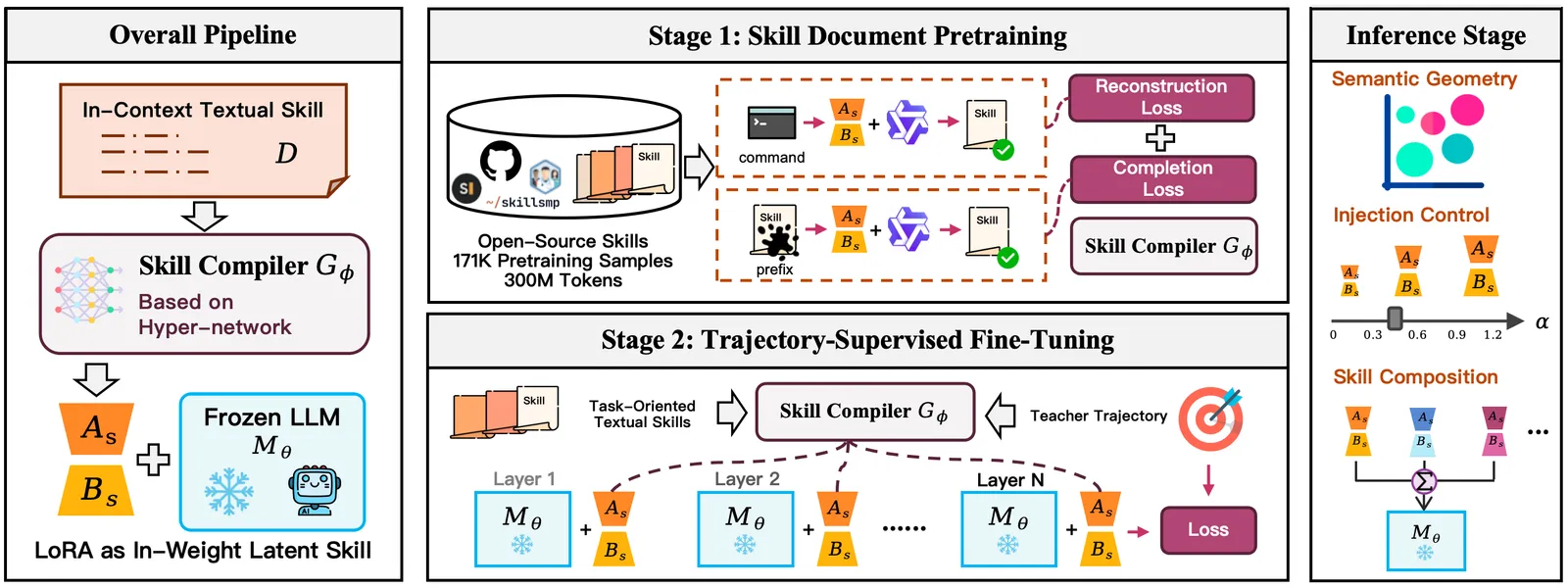
核心是超网络 G_φ,把技能文档映射成 LoRA 权重。训练分两阶段,推理则很便宜。
第一阶段,技能文档预训练:在约 17.1 万份 GitHub 技能文档(约 3 亿 token)上,用重建与续写目标训练编译器。关键巧思在于:生成的适配器必须让基座模型能复现或补全技能文本,于是知识被迫穿过适配器流动,而不是走提示词。这一步才教会 G_φ 如何把散文变成权重。
第二阶段,轨迹监督微调:在 237 条 ALFWorld 与 500 条 Search-QA 轨迹上微调。每份技能文档只生成一个适配器,并在整条轨迹里始终挂载,逼着技能在多步之间保持行为一致,而不是被逐 token 重新解读。
推理时,每个技能只编译一次进适配器缓存。挂载时用缩放系数 α 控制注入强度,基座(这里是 Qwen3-8B)照常运行。因为技能住在权重里,上下文窗口就腾出来给真正的任务和历史。
技能即可组合的权重
更有意思的是几何层面的发现。作者把生成的 LoRA 适配器做 MDS 可视化(图 3),语义相近的技能聚成一簇,域外技能则分开站位。这说明编译器学到的是一个结构化的技能空间,而非查表。
这种结构让组合成为可能,但只有谨慎的版本才奏效。论文测了三种合并策略:
- 直接合并(把完整 LoRA 相加):失败,共享分量被过度放大。
- 文本合并(先拼接技能文本再编译):失败,拼出来的文本属于分布外,行为变得不连贯。
- 分量合并(先把每个技能拆成语义子分量,分别编译,再对齐相加):成功。把「Look + Pick」组合起来,在相关回合上达到 84.6% seen / 77.8% unseen。
所以权重空间的技能算术是真的,但它发生在拆解后的分量层级,而非整块适配器。这个区分是本文最值得记住的一点。
为什么此刻重要
智能体框架越来越爱把技能库、工具文档、少样本示例一股脑塞进提示词,而这笔上下文税在长轨迹的每一步都在叠加。LatentSkill 给出一个干净的论点:其中一大块上下文其实是伪装成文本的参数,你完全可以一次编译、长期摊销。ALFWorld 上 64.1% 的 prefill 削减就是实打实的回报:每步更便宜、更快,技能却没丢。
它也绕开了「每个技能单独微调」的常规成本。因为适配器是超网络生成的,新增一个技能只是对其文档跑一次前向,而不是一轮训练。对要维护不断膨胀技能目录的团队,这才是真正吸引人的地方。
关键结果
- ALFWorld seen:成功率 74.3% 对比 in-context 的 52.9%,+21.4 分。
- ALFWorld unseen:69.4% 对比 56.0%,+13.4 分,说明编译出的技能能泛化,不只是死记。
- Prefill token(ALFWorld):比 in-context 基线少 64.1%。
- Search-QA:平均精确匹配 35.6% 对比 32.6%(+3.0),技能 token 省 72.2%(0.31k 对比 1.10k)。
- 组合:Look + Pick 分量合并达 84.6% seen / 77.8% unseen;直接合并与文本合并均退化。
- 注入系数 α:呈倒 U 型,最优值约 0.5–0.8,且因任务而异。
- 击败的基线包括 Vanilla、Few-Shot、Reflexion、AdaPlanner(ALFWorld)以及 CoT、RAG、R1-Instruct(Search-QA)。
局限与存疑
证据面偏窄。所有实验都跑在单一基座 Qwen3-8B、固定 LoRA 配置上,编译器能否跨模型家族或跨规模迁移仍是未知数。基准只有两个,即 ALFWorld 与 Search-QA,并不涵盖网页浏览、软件工程、多智能体这些技能库真正变大变乱的场景。
Search-QA 上的提升(+3.0)相比 ALFWorld(+21.4)要小得多,暗示该方法在技能偏「可复用流程」时收益最大,偏「知识检索」时则有限。注入系数 α 因任务而异、没有全局设定,这是个实打实的调参旋钮,不是白送的。分量合并还需要人工把技能拆成子分量,所以优雅的「技能算术」仍依赖手工结构。
谁该跳过:如果你智能体的「技能」主要是要去检索的事实,RAG 大概率更合适。LatentSkill 真正值回票价,是当同一个流程性技能在许多长轨迹里被反复调用、提示词税确实在割肉的时候。
常见问题
LatentSkill 和 RAG 或 in-context 技能提示有什么不同?
RAG 与 in-context 技能都在运行时把文本注入提示词,每一步都付 token。LatentSkill 只把技能编译成 LoRA 适配器一次,挂进权重,于是轨迹执行中技能几乎不占上下文 token,在 ALFWorld 上少用 64.1% 的 prefill token,成功率还更高。
LatentSkill 给每个新技能都要单独训一个模型吗?
不用。一个预训练好的超网络单次前向就能从技能文本文档生成 LoRA 适配器,所以新增技能只是对其文档做一次推理,而非一轮微调。超网络本身只在约 17.1 万份技能文档加少量轨迹上训练一次。
LatentSkill 能同时组合多个技能吗?
能,但只有分量合并奏效:把技能拆成语义子分量,在权重空间里对齐相加(例如 Look + Pick 达到 84.6% seen)。直接相加完整适配器或拼接技能文本都会失败。