ZipSplat:更少的高斯,更好的渲染
ZipSplat 用 k-means 场景 token 预测 3D 高斯,不再一像素一个。DL3DV 上 24.14 PSNR、249K 高斯胜过 YoNoSplat 的 1.2M,免位姿。
快速答案
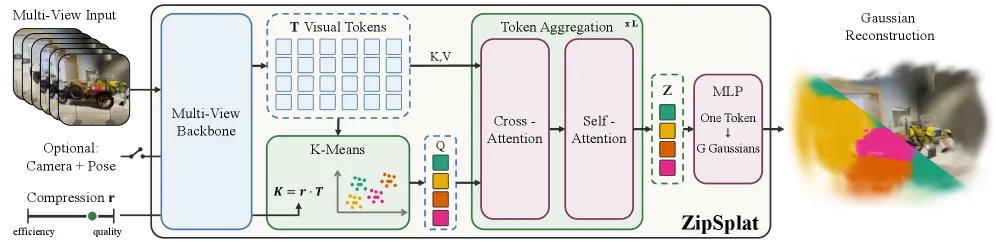
ZipSplat 是一个前馈 3D 高斯泼溅模型,它让场景需要多少高斯由内容决定,而不是由你喂进去多少像素决定。它用 k-means 把密集视觉 token 聚成一小撮场景 token,每个 token 解码出一组 32 个位置自由的高斯。DL3DV 24 视图下它拿到 24.14 PSNR,只用 249K 个高斯;YoNoSplat 是 22.01、1.2M 个,DA3 是 21.69、6.1M 个。它免位姿运行:不需要真值相机位姿或内参,补上位姿也只多约 0.1 dB。
逐像素高斯为什么浪费预算
多数前馈泼溅模型一个像素吐一个高斯。这把图元预算绑在了图像分辨率和视图数上,而不是绑在场景上。一面白墙和一棵满是枝叶的树,密度一样。视图一多,数量就炸:YoNoSplat 在 192 视图下的图元比 ZipSplat 多 90 倍,渲染慢 45 倍。冗余就是代价,而且越放大越糟。
ZipSplat 拆掉了这层绑定。骨干网(在 ViT 系的 VGGT 和 DA3-G 上都能跑)产出密集 token,k-means 再把它们压成 K = r·T 个场景 token,r 是推理时你自己选的压缩比。平坦区域塌成几个 token,细节多的区域留住很多。交叉注意力和自注意力精修这些场景 token,一个小 MLP 把每个 token 变成 32 个高斯,位置不受约束,所以单个 token 的高斯能铺开去贴合真实几何,而不是钉在某条像素射线上。
关键结果
- DL3DV,24 视图,免位姿: 24.14 PSNR / 0.768 SSIM / 0.198 LPIPS,249K 高斯;YoNoSplat 是 22.01 / 0.710 / 0.223、1.2M,DA3 是 21.69、6.1M。每项指标都更好,图元少约 5 倍。
- 同骨干正面对比: 在完全相同的骨干上,把逐像素的 DA3 解码器换成 ZipSplat 的 token 解码器,PSNR 高 1.5 到 2.7 dB,高斯少 13 到 25 倍。这把增益单独归到解码器,而不是更强的骨干。
- RealEstate10K,6 视图,免位姿: 26.20 PSNR,62K 高斯;YoNoSplat 24.99、301K。它甚至压过带真值位姿、用 393K 高斯的 DepthSplat(24.16)。
- 零样本 Mip-NeRF360,128 视图: 22.29 PSNR,1.3M 高斯;DA3 是 20.19、32.5M,在没训过的数据上少了 25 倍。
- 速度: 192 视图下渲染 401 FPS(102K 高斯),24 视图下 685 FPS;前向 24 视图下不到 0.8 秒、8.1 GB。
- 每个 token 给多少高斯: 32 个时质量就饱和了;翻倍到 64 个只多 0.03 dB,预算却翻倍。
压缩比到底在调什么
压缩比 r 是这里最有意思的旋钮。一个训好的模型靠推理时改 r,就能覆盖整条质量对数量的曲线;题图把同一个 ZipSplat 画成几颗红星散在曲线上。r=0.1 时它已经用约 24 倍更少的高斯压过 YoNoSplat。但有下限:论文设 r_min = 0.5·sqrt(2/N),让 token 数跟得上视图数 N,把 r 压到 0.01 以下就开始整片整片地丢场景区域。所以这个旋钮真能用,但有边界,合适的值取决于你喂多少视图。
局限与存疑
高斯更少不等于处处更锐。逐像素方法把输入颜色直接嵌进每个高斯,保住了高频纹理;ZipSplat 从聚合 token 里预测,所以稀疏视图下它在 LPIPS 上落后,即便 PSNR 和 SSIM 领先。k-means 的分配也会判断失准:它把高斯堆给杂乱的植被,饿着平坦表面,遇到运动物体或上下文重叠很少的目标也会掉。消融显示这套系统经不起拆:耦合初始化值 0.25 dB,几何损失光是为了训练稳定就少不了,所以它是一条调好的管线,不是即插即用的解码器。论文把图元数和速度摆在前面,却很少谈训练数据规模和成本,想复现的人会在意这点。还有几处对比把免位姿和需位姿的基线混着摆,所以看每张表前先确认它实际用的是哪种设置,再下”干净胜出”的结论。
常见问题
ZipSplat 怎么做到比逐像素方法少 6 到 33 倍的高斯?
它不再一像素一个高斯。k-means 把骨干的密集 token 聚成 K = r·T 个场景 token,每个 token 解码 32 个位置自由的高斯。因为聚类跟着场景内容走,平坦区域用很少 token,细节区域留更多。减少幅度从匹配设置下的 6 倍,到同骨干对逐像素解码器的 24 倍,再到与 YoNoSplat 同质量时的 33 倍。
ZipSplat 需要相机位姿或内参吗?
不需要。它免位姿地重建和渲染,无需真值位姿或内参,在 DL3DV 和 RealEstate10K 上压过其他免位姿基线。有位姿时,把它作为可选相机先验喂进去也只多约 0.1 dB,所以免位姿是主线,不是退路。
ZipSplat 在哪些地方不如逐像素高斯泼溅?
稀疏视图和高频纹理上。逐像素方法把输入颜色直接注入每个高斯,保住细节,所以少视图下 ZipSplat 在 LPIPS 上落后,尽管 PSNR 和 SSIM 更高。它的 k-means 分配还会过度服务复杂植被、亏待平坦表面,运动物体上质量也会掉。
ZipSplat 是每个质量档一个模型,还是一个模型管全部?
一个模型。压缩比 r 在推理时设定,所以一个训好的 ZipSplat 覆盖整条质量对高斯数量的曲线。r=0.1 时它已经用约 24 倍更少的高斯超过 YoNoSplat,实用下限是与视图数 N 挂钩的 r_min = 0.5·sqrt(2/N)。
一句话:ZipSplat 表明前馈泼溅的高斯预算该跟着场景复杂度走,不该跟着像素数走,换来 6 到 33 倍更少的图元、45 倍更快的渲染,PSNR 还更高。阅读 arXiv 原文,想看 3D 视觉方向可参考 VLM3。