AutoResearchClaw: An AI Research Agent That Beats AI Scientist v2
AutoResearchClaw is a 23-stage multi-agent system for autonomous ML research. It scores 0.648 vs AI Scientist v2's 0.419 on its 25-topic ARC-Bench, and rises to 7.27/10 quality with a human in the loop.
Quick answer
AutoResearchClaw is a multi-agent system that runs a full machine-learning research project (hypothesis, code, experiments, analysis) through a fixed 23-stage pipeline, with a human able to step in at any stage. On its own ARC-Bench (25 ML topics), it reaches an overall strict score of 0.648 versus 0.419 for AI Scientist v2, a 54.7% relative improvement, and 0.511 for AIDE-ML. The headline finding is not the autonomy: it is that a human-in-the-loop “CoPilot” mode lifts mean output quality to 7.27/10 with an 87.5% accept rate, while the fully autonomous mode sits at 4.03/10 and 25%.
The problem with “AI scientists”
Autonomous research agents keep failing in the same two ways: they hallucinate results that were never actually computed, and one bad early decision (a broken data split, a wrong metric) silently poisons everything downstream with no recovery. AutoResearchClaw is built around the claim that you fix these by structuring the workflow and keeping a human reachable, not by making a single agent smarter. That framing is the paper’s real argument, and the benchmark numbers exist mainly to defend it.
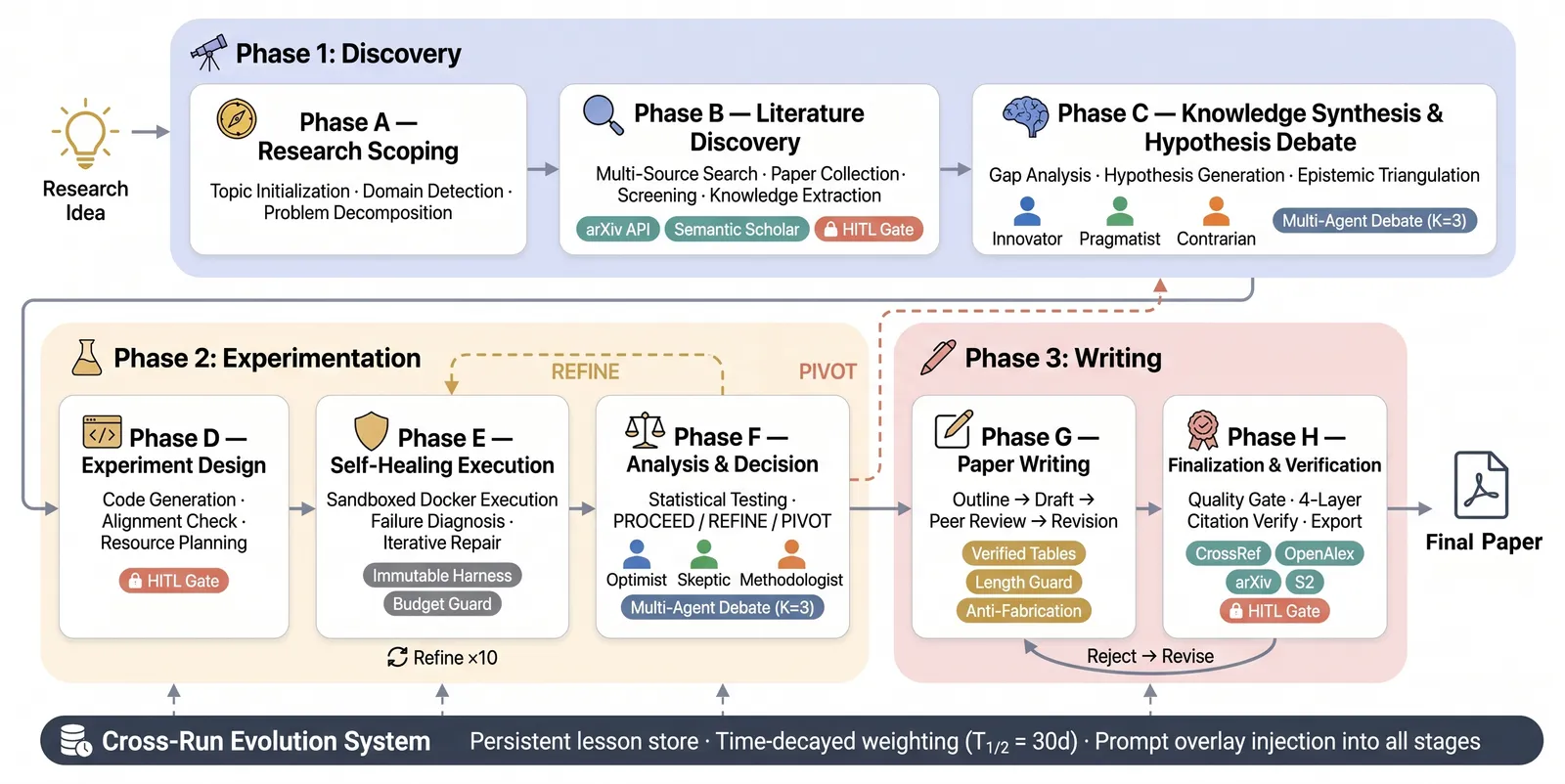
How the 23-stage pipeline works
The system decomposes research into 23 stages across three phases (ideation, experimentation, reporting). Two parts carry most of the weight:
- Structured multi-agent debate. For hypothesis generation and again for result analysis, the system runs panels of K=3 agents assigned complementary epistemic roles (e.g. a proposer, a skeptic, a synthesizer) rather than a single chain-of-thought. The debate is the mechanism meant to raise idea quality and catch flawed reasoning before it costs a compute run.
- Verification against fabrication. A dedicated checking step ties reported numbers back to actual executed code and logged outputs, which is the paper’s answer to the result-hallucination failure mode that plagues prior agents.
Layered on top is failure recovery (when a stage errors, the system can retry or reroute instead of crashing the run) and seven human intervention modes, from fully autonomous to step-by-step approval.
Key results
- Overall ARC-Bench strict score: 0.648 for AutoResearchClaw versus 0.419 for AI Scientist v2, a 54.7% relative gain, and 0.511 for AIDE-ML (a 26.8% gain).
- Result Analysis dimension: 0.523 vs 0.261, a 100.4% relative improvement, the largest of any dimension and the one the debate-plus-verification design most directly targets.
- Code execution success: 0.578 vs 0.442 for AI Scientist v2; code development scores 0.968 in CoPilot mode.
- Human-in-the-loop (10 topics, Table 3): CoPilot mode reaches 7.27 mean quality with an 87.5% accept rate over 6 interventions, against 4.03 / 25.0% for Full-Auto and 5.19 / 50.0% for Step-by-Step (which needed 23 interventions for a worse result).
- Domain breadth: beyond the 25 core ML topics, 20 scientific tasks (10 high-energy physics, 7 systems biology, 3 statistics) score 0.489 (physics), 0.912 (biology), and 0.898 (statistics).
Why the human-in-the-loop number is the honest one
The most useful result here is the gap between Full-Auto (4.03/10) and CoPilot (7.27/10). It is a quiet admission that the fully autonomous system is not yet trustworthy (25% of its outputs were acceptable) and that the real product is a research assistant with a human reviewer, not an autonomous scientist. CoPilot also beats Step-by-Step (5.19) while using far fewer interventions (6 vs 23), suggesting that where a human intervenes matters more than how often. That is a more defensible claim than “we automated science.”
Limits and open questions
The benchmark is the authors’ own (ARC-Bench), and the strongest baseline comparison is against AI Scientist v2 and AIDE-ML. There is no human-researcher control, so “0.648” has no absolute ceiling to anchor against. The human-in-the-loop results rest on just 10 topics with subjective 0–10 quality scores, a thin and partly judgmental sample. Cost and wall-clock time of running a 23-stage, multi-debate, multi-agent pipeline are not the focus, and debate with K=3 agents multiplies token spend. The scientific-domain tasks span only three fields with as few as three statistics tasks, so the cross-domain claim is suggestive rather than established. As with all autonomous-research work, faithful verification is asserted by design but hard to guarantee against a sufficiently confident model.
FAQ
What is AutoResearchClaw?
AutoResearchClaw is a multi-agent AI system that carries out machine-learning research end to end through a 23-stage pipeline: generating hypotheses via structured debate, writing and running code, analyzing results, and verifying them, with optional human intervention at any stage.
How much better is AutoResearchClaw than AI Scientist v2?
On its 25-topic ARC-Bench, AutoResearchClaw scores 0.648 versus 0.419 for AI Scientist v2 on the overall strict metric, a 54.7% relative improvement, with its largest gain (100.4%) on the result-analysis dimension.
Does AutoResearchClaw work fully autonomously?
It can, but not well: in fully autonomous mode it scores 4.03/10 mean quality with a 25% accept rate. Its CoPilot human-in-the-loop mode reaches 7.27/10 and 87.5%, so the paper’s strongest configuration keeps a human reviewer in the loop.
What stops AutoResearchClaw from fabricating results?
A dedicated verification stage ties every reported number back to actually executed code and logged outputs, directly targeting the result-hallucination failure that affects prior autonomous research agents.
One line: structure the workflow and keep a human reachable, and an AI research agent goes from 25% to 87.5% usable. Read the original paper on arXiv.