AutoResearchClaw:跑赢 AI Scientist v2 的科研智能体
AutoResearchClaw 用 23 阶段多智能体管线自主做研究,ARC-Bench 上 0.648 远超 AI Scientist v2 的 0.419,但只有人在环时质量才达标。
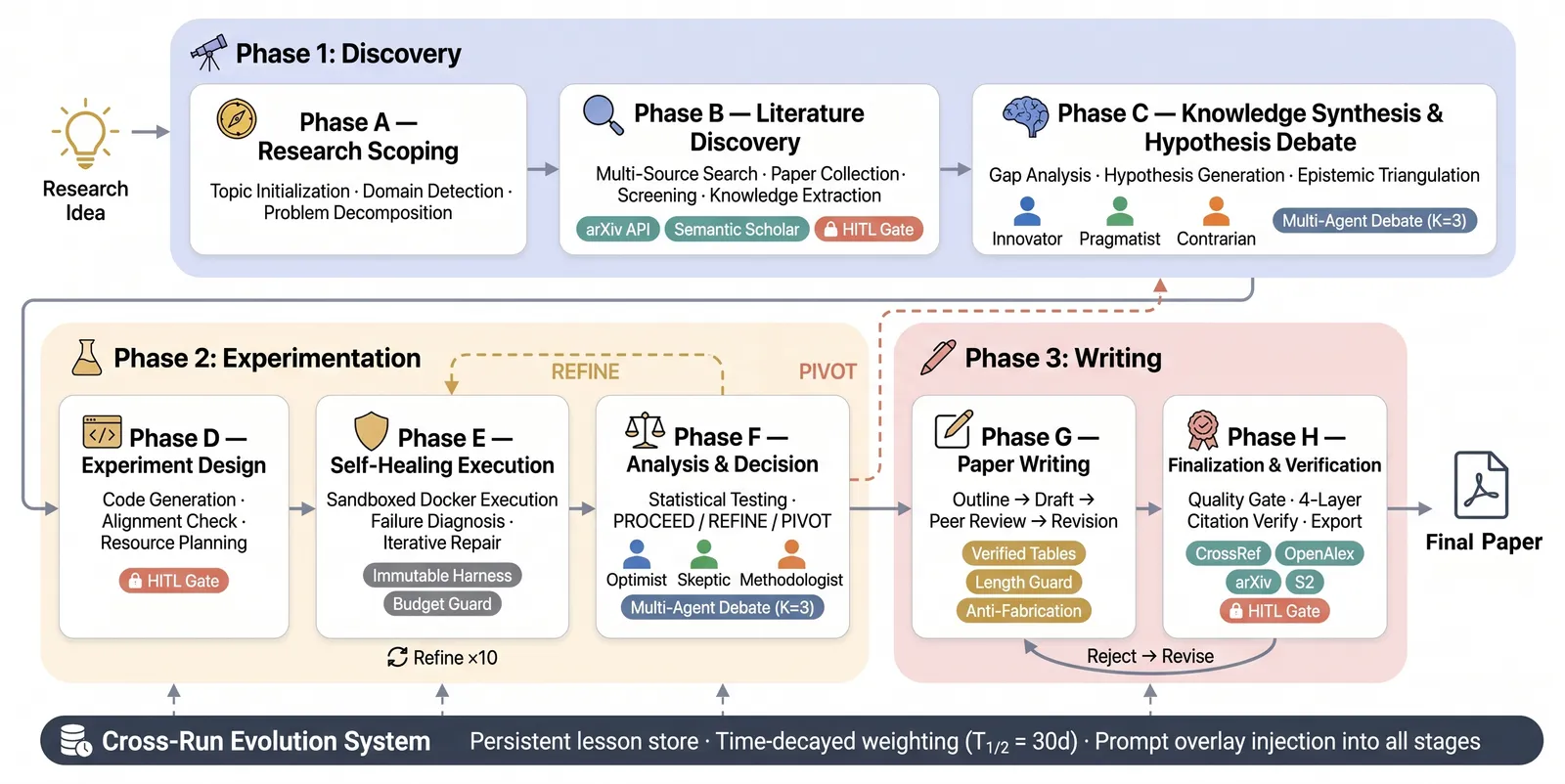
快速答案
AutoResearchClaw 是一套多智能体系统,用固定的 23 阶段管线跑完一个机器学习研究项目(提假设、写代码、跑实验、做分析),并允许人在任意阶段介入。在自建的 ARC-Bench(25 个 ML 课题)上,它的整体严格分达 0.648,而 AI Scientist v2 为 0.419,相对提升 54.7%,AIDE-ML 为 0.511。真正的看点不在自主性。人在环的「CoPilot」模式把平均输出质量拉到 7.27/10、接受率 87.5%,而全自动模式只有 4.03/10、25%。
「AI 科学家」卡在哪里
自主科研智能体总在两处翻车:一是凭空编造从未真正算出的结果,二是早期一个错误决策(数据划分坏了、指标选错了)悄悄毒化下游全部流程且无从恢复。AutoResearchClaw 的核心主张是:解决这两点靠的是把工作流结构化、并让人始终可被触及,而不是把单个智能体做得更聪明。这才是论文真正的论点,基准数字主要是为这个论点辩护。
23 阶段管线怎么运作
系统把研究拆成三个阶段(构思、实验、报告)下的 23 个步骤。其中两块最关键:
- 结构化多智能体辩论。 在假设生成、再到结果分析两处,系统各跑一个 K=3 的智能体辩论组,给它们分配互补的认知角色(如提议者、质疑者、综合者),而不是单条思维链。辩论正是用来提升点子质量、在烧算力之前抓出错误推理的机制。
- 对抗造假的核验。 一个专门的核验步骤把上报的每个数字与实际执行的代码、记录的输出对上,这是论文对「结果幻觉」这一老毛病的回应。
在此之上叠了失败恢复(某阶段报错时系统可重试或改道,而非整轮崩溃),以及从全自动到逐步审批的七种人在环介入模式。
关键结果
- ARC-Bench 整体严格分:0.648(AutoResearchClaw)对 0.419(AI Scientist v2),相对提升 54.7%;对 AIDE-ML 的 0.511 则提升 26.8%。
- 结果分析维度:0.523 对 0.261,相对提升 100.4%,是所有维度里最大的,也正是辩论加核验设计最直接针对的环节。
- 代码执行成功率:0.578 对 0.442(AI Scientist v2);CoPilot 模式下代码开发分达 0.968。
- 人在环(10 个课题,表 3): CoPilot 模式以 6 次介入达到 7.27 平均质量、87.5% 接受率;全自动为 4.03 / 25.0%;逐步模式为 5.19 / 50.0%,且用了 23 次介入却更差。
- 跨领域: 除 25 个核心 ML 课题外,20 个科学任务(10 个高能物理、7 个系统生物学、3 个统计)分别得 0.489(物理)、0.912(生物)、0.898(统计)。
为什么人在环的数字才诚实
这里最有用的结果是全自动(4.03/10)与 CoPilot(7.27/10)之间的落差。它等于悄悄承认:全自动系统还不可信(只有 25% 的输出可接受),真正能用的产品是一个带人工复核的科研助手,而非自主科学家。CoPilot 还以远少的介入次数(6 次对 23 次)赢过逐步模式(5.19),说明人「在哪里」介入比介入多少次更重要。这比「我们把科研自动化了」是一个更站得住的说法。
局限与存疑
基准是作者自建的(ARC-Bench),最强的对照只是 AI Scientist v2 与 AIDE-ML。没有人类研究者作对照,所以 0.648 没有绝对天花板可锚定。人在环结果只基于 10 个课题、用主观的 0–10 打分,样本既薄又含判断成分。跑一条 23 阶段、多轮辩论、多智能体的管线,其成本与耗时不是论文重点,而 K=3 的辩论会成倍放大 token 开销。科学领域任务只覆盖三个学科,统计任务少到只有 3 个,跨领域结论是提示性的而非已被确立。一如所有自主科研工作,核验的「忠实」由设计声称,却很难对一个足够自信的模型保证到位。
常见问题
AutoResearchClaw 是什么?
AutoResearchClaw 是一套多智能体 AI 系统,通过 23 阶段管线端到端完成机器学习研究:用结构化辩论生成假设、写并运行代码、分析结果并加以核验,且可在任意阶段由人介入。
AutoResearchClaw 比 AI Scientist v2 强多少?
在 25 课题的 ARC-Bench 上,AutoResearchClaw 整体严格分 0.648,AI Scientist v2 为 0.419,相对提升 54.7%;其最大增益(100.4%)出现在结果分析维度。
AutoResearchClaw 能完全自主运行吗?
能,但不好:全自动模式平均质量只有 4.03/10、接受率 25%。其 CoPilot 人在环模式达到 7.27/10 与 87.5%,所以论文最强配置始终保留人工复核。
AutoResearchClaw 怎么防止编造结果?
一个专门的核验阶段把上报的每个数字与实际执行的代码、记录的输出对上,直接针对困扰以往自主科研智能体的「结果幻觉」问题。
一句话:把工作流结构化、让人随时可介入,科研智能体的可用率就能从 25% 升到 87.5%。阅读 arXiv 原文。