Pi-Bench: Can AI Assistants Anticipate What You Did Not Say?
Pi-Bench scores agents on proactivity, not just task completion, across 100 long-horizon tasks. The best model, GPT-5.4, hits only 67.0% proactivity, and removing prior sessions drops it 9.5 points.
Quick answer
Pi-Bench measures whether an AI assistant resolves needs the user never stated out loud, not just whether it finishes the assigned task. Across 100 multi-turn tasks over five professional personas, the strongest model, GPT-5.4, reaches only 67.0% proactivity and 65.6% completeness; Claude Opus 4.6 trails at 65.5% / 67.6%. The headline finding is that proactivity and completeness are different skills. A model can finish the checklist while ignoring everything the user implied.
Why “proactive” is the hard part
Most agent benchmarks reward an assistant for executing an explicit instruction. Pi-Bench inverts the test. Every task carries an initial request, a set of hidden intents (latent requirements the user never spells out), and a checklist of verifiable deliverables. A reactive agent that only does what it is told can pass the checklist while missing every hidden intent. The benchmark’s whole point is to separate “did the work” from “understood the person,” because in a real long-running assistant relationship the second one is what users actually notice.
How Pi-Bench is built
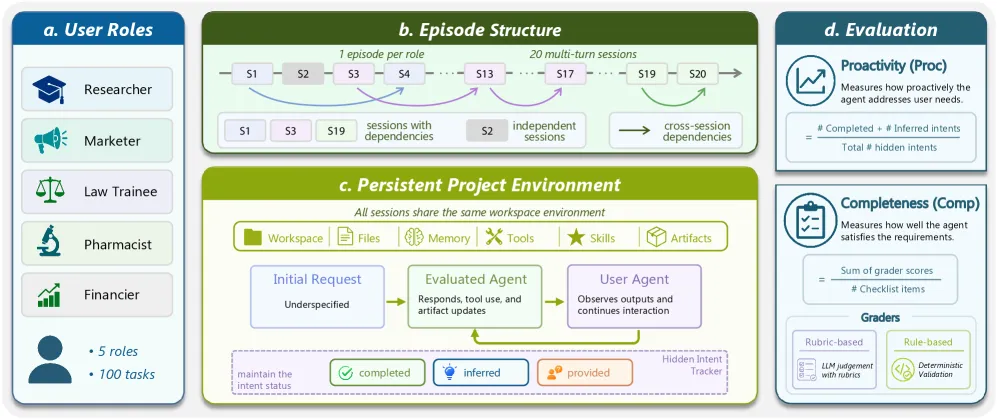
The benchmark spans five domain personas (Researcher, Marketer, Law Trainee, Pharmacist, Financier), each running an episode of 20 sessions inside a persistent project environment where artifacts accumulate across sessions. That persistence is deliberate. Six strong dependency groups, each two to three tasks, require the agent to carry context forward, so a session is not a clean slate. This is the design choice that makes the benchmark “long-horizon” rather than a pile of one-shot prompts.
Two scores define performance. Proactivity (Proc) is the fraction of hidden intents the agent resolves on its own, set against the intents a user had to volunteer unprompted (Provided). It resolves an intent either by directly completing it (Completed) or by asking a focused question that surfaces the requirement (Inferred). Completeness (Comp) is whether the agent satisfies the verifiable checklist, scored by rule-based or rubric graders. Splitting the two is the contribution. It lets you see an agent that quietly does extra right things alongside one that mechanically clears the checklist while staying oblivious.
Key results
- GPT-5.4 leads on proactivity at 67.0% (+/-2.1), with 65.6% completeness. Claude Opus 4.6 is close behind at 65.5% Proc and the best completeness, 67.6%. Qwen3.6 Plus follows at 64.0% / 64.1%.
- Proactivity ranges 43.1% to 67.0% across the nine models tested, a 24-point spread, while completeness sits in a tighter 52.1% to 67.6% band. No frontier model clears 70% proactivity; the authors conclude proactive assistance “remains challenging.”
- The two skills come apart. Kimi K2.5 posts 61.6% completeness but only 43.1% proactivity (it clears checklists reactively); Seed2.0 Pro is the mirror image at 58.4% Proc and just 52.1% Comp (good at surfacing intent, weak at executing it).
- Memory of prior sessions is doing real work. Stripping the preceding sessions out of dependency groups drops proactivity by 9.5 points on average but completeness by only 2.5. GPT-5.4 falls from 78.5% to 64.9% proactivity while its completeness barely moves. That is strong evidence that current agents lean on accumulated context to anticipate, and degrade sharply without it.
- Domain gaps are large. Legal handoffs show 84.1% completeness against just 38.1% proactivity (the widest gap); drug-design tasks flip it, 84.9% proactivity but 68.0% completeness.
The honest read
The most useful number here is the 9.5-point proactivity drop when prior sessions are removed. It quantifies something the field usually only asserts: today’s “proactive” behavior is largely the model exploiting context it was handed, not genuine modeling of a persistent user. The 24-point spread between models also says proactivity is not yet a solved, commoditized capability. There is real headroom and real differentiation here, which makes this a benchmark worth tracking rather than one that saturates next quarter.
Limits and open questions
The users are simulated, not real humans, so the hidden intents reflect what the benchmark authors decided a Researcher or Pharmacist would want. That is a reasonable proxy, but proactivity judged against scripted personas can reward pattern-matching to the benchmark rather than true anticipation. Evaluation also runs on a single agentic scaffold adapted from Nanobot, so the scores may shift with a different harness, tool set, or memory implementation; the model ranking is not guaranteed to be scaffold-independent. And with 100 tasks and five personas, coverage is deliberately deep but narrow: strong for measuring long-horizon dependency, weaker as a claim about assistants in the open world.
FAQ
What does Pi-Bench actually measure?
Pi-Bench measures proactivity, the fraction of a user’s unstated, hidden intents that an agent resolves on its own, separately from completeness, the fraction of explicit checklist deliverables it satisfies. The split lets you tell apart an agent that anticipates needs from one that just follows orders.
Which model is best on Pi-Bench?
GPT-5.4 leads proactivity at 67.0%, with Claude Opus 4.6 close behind at 65.5% and the highest completeness at 67.6%. No model among the nine tested exceeds 70% proactivity, so the authors call proactive assistance still unsolved.
Why does removing prior sessions matter in Pi-Bench?
Removing the preceding sessions in a dependency group cuts proactivity by an average of 9.5 points but completeness by only 2.5. That shows current agents rely heavily on accumulated context to anticipate needs, rather than reliably modeling a persistent user from scratch.
How is Pi-Bench different from other agent benchmarks?
Most agent benchmarks score whether the explicit task got done. Pi-Bench adds hidden intents and long-horizon, cross-session dependencies (100 tasks across five personas, each a 20-session episode) to test whether an assistant anticipates needs over a sustained relationship, not in a single turn.
One line: finishing the checklist is not the same as understanding the user, and Pi-Bench puts a number on the gap. Read the original paper on arXiv.