Pi-Bench:AI 助手能猜到你没说出口的需求吗
Pi-Bench 不只看完成度,更测「主动性」。100 个长程任务里最强的 GPT-5.4 主动性也只有 67.0%,抽走历史会话后骤降 9.5 个百分点。
快速答案
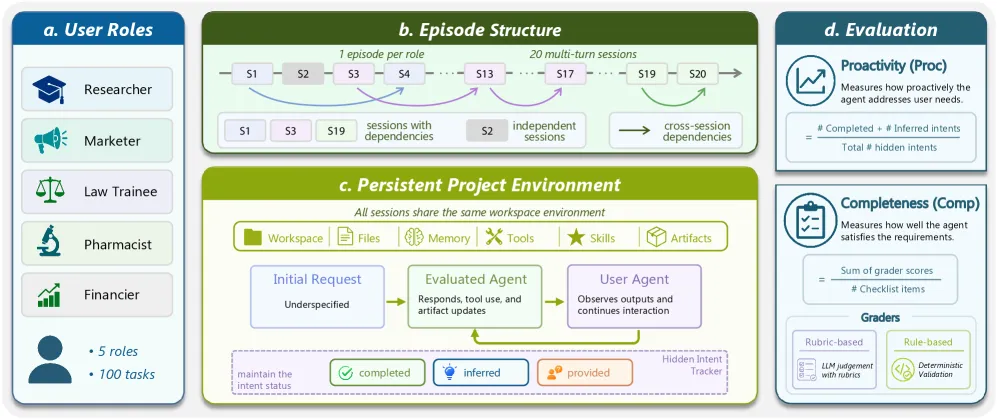
Pi-Bench 测的是 AI 助手能否解决用户没说出口的隐性需求,而不只是把指定任务做完。在覆盖五种职业人设的 100 个多轮任务上,最强的 GPT-5.4 主动性仅 67.0%、完成度 65.6%;Claude Opus 4.6 紧随其后,为 65.5% / 67.6%。最关键的发现是:主动性和完成度是两种不同能力。模型可以把清单全部勾完,却对用户的言外之意一无所知。
「主动」为什么是最难的部分
多数智能体基准奖励助手「把明确指令执行掉」。Pi-Bench 把考题反了过来。每个任务都带一条初始请求、一组隐性意图(用户从未明说的潜在需求),以及一份可核验的交付清单。一个只做被吩咐之事的被动智能体,完全可以通过清单、却漏掉每一个隐性意图。基准的全部用意,就是把「活干了」和「人读懂了」拆开,因为在真实的长期助手关系里,用户真正在意的是后者。
Pi-Bench 怎么搭起来的
基准覆盖五种领域人设(研究员、市场营销、法务实习、药剂师、金融从业者),每种人设跑一个包含 20 个会话的 episode,置身于一个长期延续的项目环境中,产出物会跨会话累积。这种延续性是刻意设计的:六个强依赖组(每组两到三个任务)要求智能体把上下文一路带下去,于是任何一个会话都不是一张白纸。正是这一设计,让它成为「长程」基准,而非一堆一次性提示词的堆砌。
衡量表现的有两个分数。主动性(Proc) 是智能体自己解决掉的隐性意图占比,与之相对的是用户不得不主动补充的意图(Provided)。智能体既可以直接完成(Completed),也可以抛出一个精准问题让需求浮现(Inferred)。完成度(Comp) 则看智能体是否满足可核验清单,由规则或评分细则打分。把两者拆开正是本文的贡献:它让你能同时看见一个默默把额外正确事情做掉的智能体,和一个机械勾完清单却浑然不觉的智能体。
关键结果
- GPT-5.4 主动性居首,67.0%(±2.1),完成度 65.6%。 Claude Opus 4.6 紧随其后,主动性 65.5%、完成度最高达 67.6%;Qwen3.6 Plus 为 64.0% / 64.1%。
- 九个受测模型的主动性从 43.1% 到 67.0%,跨度 24 个百分点;完成度则集中在 52.1% 到 67.6% 这一更窄区间。没有任何前沿模型主动性过 70%,作者据此断定:主动式辅助「仍然很难」。
- 两种能力会分家。 Kimi K2.5 完成度 61.6%、主动性却只有 43.1%(被动地勾清单);Seed2.0 Pro 恰好相反,主动性 58.4%、完成度仅 52.1%(善于挖出意图,却执行乏力)。
- 历史会话的记忆真在起作用。 把依赖组里在前的会话抽掉,主动性平均下降 9.5 个百分点,完成度却只跌 2.5。GPT-5.4 的主动性从 78.5% 跌到 64.9%,完成度几乎不动。这有力地说明:当前智能体靠累积的上下文来「预判」,一旦没有就急剧退化。
- 领域差异巨大。 法务交接任务完成度 84.1%、主动性却只有 38.1%(差距最大);药物设计任务则反过来,主动性 84.9%、完成度 68.0%。
一点直话
这里最有价值的数字是抽走历史会话后主动性掉的 9.5 个百分点。它把领域里常被断言、却少被量化的事情量化了:今天所谓的「主动」,很大程度上是模型在利用别人递给它的上下文,而非真正建模了一个长期延续的用户。模型之间 24 个百分点的跨度也说明,主动性远未变成已解决、被商品化的能力。这里既有真实的上升空间,也有真实的区分度,这让它成为一个值得长期跟踪、而非下季度就饱和的基准。
局限与存疑
这里的用户是模拟的,不是真人,因此隐性意图反映的是基准作者认为某个研究员或药剂师会想要什么。这是个合理的代理,但用脚本化人设来评判主动性,可能奖励的是「对基准的模式匹配」而非真正的预判。评测还跑在单一智能体脚手架上(改编自 Nanobot),换一套框架、工具集或记忆实现,分数与排名都未必稳固,不能保证与脚手架无关。而 100 个任务、五种人设的设计是刻意「深而窄」的:衡量长程依赖很有力,作为对开放世界助手的论断则偏弱。
常见问题
Pi-Bench 到底测什么?
Pi-Bench 把主动性(智能体自己解决掉的、用户未明说的隐性意图占比)和完成度(满足的明确清单交付占比)分开来测。这种拆分让你能区分一个会预判需求的智能体,和一个只会照章办事的智能体。
Pi-Bench 上哪个模型最强?
GPT-5.4 主动性居首,67.0%;Claude Opus 4.6 紧随其后,主动性 65.5%、完成度最高 67.6%。九个受测模型无一主动性超过 70%,因此作者认为主动式辅助仍未被攻克。
Pi-Bench 里抽走历史会话为何重要?
把依赖组中在前的会话抽掉,主动性平均下降 9.5 个百分点,完成度却只跌 2.5。这说明当前智能体高度依赖累积的上下文来预判需求,而非能从零稳健地建模一个持久用户。
Pi-Bench 与其他智能体基准有何不同?
多数智能体基准只看明确任务有没有做完。Pi-Bench 加入了隐性意图与长程跨会话依赖(100 个任务、五种人设,每种是一个 20 会话的 episode),用以检验助手能否在一段持续关系中预判需求,而非只在单轮里表现。
一句话:勾完清单不等于读懂了用户,而 Pi-Bench 给这道鸿沟标上了数字。阅读 arXiv 原文。