Efficient AI · Language Models
Draft-OPD: On-Policy Distillation Pushes Speculative Decoding Past 5x
Draft-OPD trains speculative draft models on states their own drafting induces, not just target transcripts. On Qwen3 thinking models it hits 4.86x to 4.89x, beating EAGLE-3 by 23 percent and DFlash by 13 percent.
Quick answer
Draft-OPD is an on-policy training recipe for the small draft model used in speculative decoding. Instead of imitating only the target model’s transcripts, it supervises the draft model on the states its own drafting produces at inference time, including the positions where its proposals get rejected. On Qwen3 thinking models it reaches 4.86x speedup on Qwen3-4B and 4.89x on Qwen3-8B, against 3.87x and 4.06x for EAGLE-3 and 4.33x and 4.34x for DFlash. Averaged across benchmarks, that is a 23 percent gain over EAGLE-3 and 13 percent over DFlash under matched compute. Decoding stays lossless: the target model’s output distribution is preserved, so quality does not change.
The problem: draft models trained offline drift at inference
Speculative decoding accelerates a large target model by letting a small draft model propose several tokens, which the target then verifies in one pass. The catch is the draft model’s training. Methods like EAGLE-3 and DFlash train the draft via supervised fine-tuning on the target model’s own generated text. That is offline data: the draft never sees the states it will actually visit once it starts proposing tokens autoregressively. The paper calls this an offline-to-inference mismatch. The visible symptom is that accepted length plateaus during SFT training, so adding more imitation data stops helping. The draft model is good at predicting the target’s transcript but bad at recovering from its own mistakes, which is exactly the situation speculative verification creates.
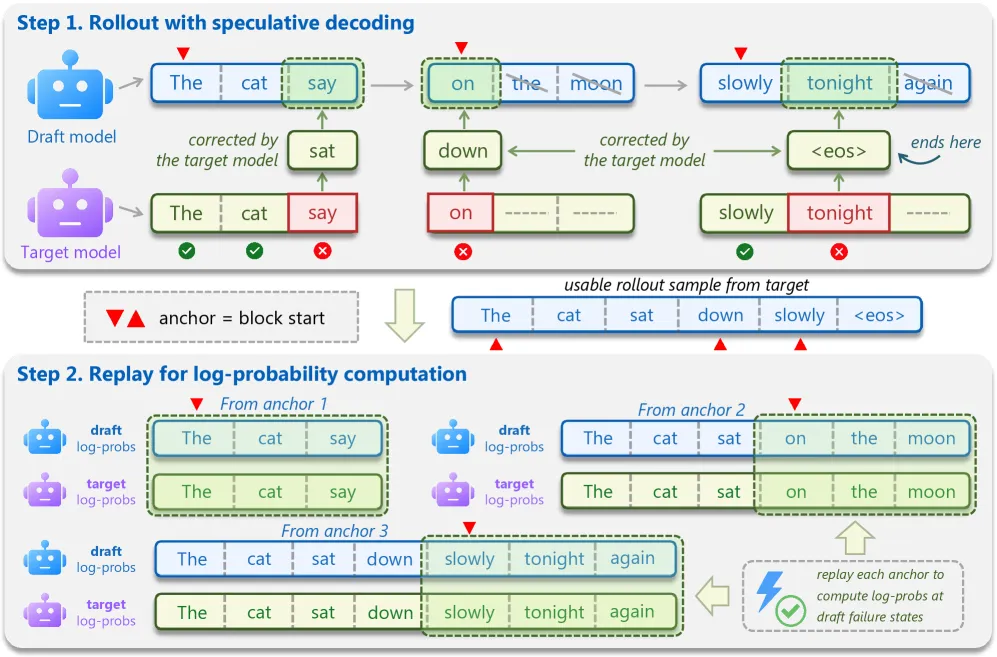
The method: target-assisted rollout plus error-position replay
Draft-OPD borrows the on-policy idea from reinforcement learning but adapts it to drafting. Naive on-policy distillation does not work for draft models, because letting the draft generate freely produces unstable, off-distribution sequences that the target would never accept.
The fix has two parts. Target-assisted rollout runs ordinary speculative decoding to collect high-quality continuations, while recording anchor positions where each draft block began. This keeps the sequence on the target’s distribution but still captures what the draft actually did. Error-position replay then re-runs drafting from each anchor position and computes both student and teacher log-probabilities on the draft-generated tokens, crucially including the rejected proposals that mark where the draft erred.
The training objective is an asymmetric KL divergence: forward KL on accepted tokens, where the draft and target already agree, and reverse KL on rejected tokens, which penalizes the draft for putting mass on continuations the target refuses. A position-weighted decay emphasizes early rejections within a block, since those cost the most accepted length. The net effect is that the draft model learns from both its hits and its misses, which plain SFT cannot do because SFT never observes the misses.
Why this matters now
Thinking models generate long reasoning chains, so token-by-token decoding latency dominates their cost. Speculative decoding is the standard answer, but the draft model is the bottleneck, and SFT-trained drafts had hit a ceiling. Draft-OPD raises that ceiling without touching the target model or sacrificing output quality, which makes it a drop-in upgrade for inference stacks already running EAGLE-3 or DFlash style drafts.
Key results
- Qwen3-4B (thinking, temperature 0): Draft-OPD 4.86x speedup, acceptance length tau 5.96; DFlash 4.33x, tau 5.51; EAGLE-3 3.87x, tau 5.33.
- Qwen3-8B (thinking, temperature 0): Draft-OPD 4.89x, tau 5.73; DFlash 4.34x, tau 5.19; EAGLE-3 4.06x, tau 5.64.
- Aggregate gain: about 23 percent over EAGLE-3 and 13 percent over DFlash under matched compute budgets.
- Headline claim: over 5x lossless acceleration for thinking models across diverse tasks, with non-thinking mode reaching higher per-task peaks.
- Quality: decoding is distribution-preserving, so generation quality is unchanged by design.
- Evaluation suite: GSM8K, MATH-500, AIME, MBPP, HumanEval, SWE-Lite, and MT-Bench, on Qwen3-4B, Qwen3-8B, and Qwen3-30B-A3B-Thinking.
Limits and open questions
The training length is capped at 4,096 tokens while evaluation runs to 8,192, so the draft model is trained on shorter contexts than it is tested on. Evaluation is confined to the Qwen3 family and DFlash-style draft architectures; whether the gains transfer to other model families or draft designs is untested here. The method targets speed only, not quality, so it offers nothing to tasks where the target model itself is the limiting factor. And the headline 5x figure aggregates across benchmarks and modes, so individual tasks vary; the cleaner apples-to-apples numbers are the per-model speedups above. There is also added training complexity: the rollout-and-replay loop is heavier than a single SFT pass.
FAQ
What does on-policy mean in Draft-OPD?
It means the draft model is supervised on the states induced by its own drafting policy during speculative decoding, rather than only on fixed target-generated transcripts. That closes the offline-to-inference mismatch that caps SFT-trained drafts.
Does Draft-OPD change the output of the target model?
No. Speculative decoding preserves the target model’s output distribution, and Draft-OPD is explicitly designed to improve decoding speed, not generation quality. Outputs are the same as standard decoding from the target model.
How is it different from EAGLE-3 and DFlash?
EAGLE-3 and DFlash train the draft with supervised fine-tuning on offline target text. Draft-OPD adds target-assisted rollout to stay on-distribution and error-position replay to learn from rejected proposals, then trains with an asymmetric forward and reverse KL objective. On Qwen3 thinking models that yields 23 percent and 13 percent higher speedups respectively.