Video Generation · World Models
Echo-Infinity: Learnable Evolving Memory for 24-Hour Real-Time Video
Echo-Infinity is an autoregressive video model with a learnable evolving memory that compresses any-length history at constant cost, hitting 24-hour rollouts (over 1.3M frames) in real time at 18.5 FPS on an H100.
Quick answer
Echo-Infinity is an autoregressive (AR) video diffusion model that generates effectively infinite video by learning what to remember instead of hand-coding it. It replaces fixed KV-cache schedules and heuristic compression with a learnable evolving memory, runs at 18.5 FPS on a single H100, and demonstrates 24-hour rollouts exceeding 1.3 million frames in real time, which the authors say is the first such demonstration. On VBench-Long it scores 85.61 at 30 seconds and 82.01 at 240 seconds, holding quality far longer than memory schemes that drift as the cache window fills up. It comes from a team across CUHK, HKUST, Tsinghua, HKU, Peking University, USTC, and JD Joy Future Academy.
The problem: memory is the bottleneck for long video
Frame-by-frame AR video models can in principle run forever, but each new frame must attend to history, and history grows without bound. Every prior infinite-video method curates that history with a predefined rule: a fixed KV-cache window, a fixed-ratio compression heuristic, or inference-time RoPE adaptation. All three throw away information the same way every time, regardless of what the video actually contains, and none of them account for the noise that AR generation injects into its own past frames. The result is compounding error: the longer you roll out, the more the model drifts off the scene it started in. The real question is not how to store more frames cheaply, but how to decide what is worth keeping.
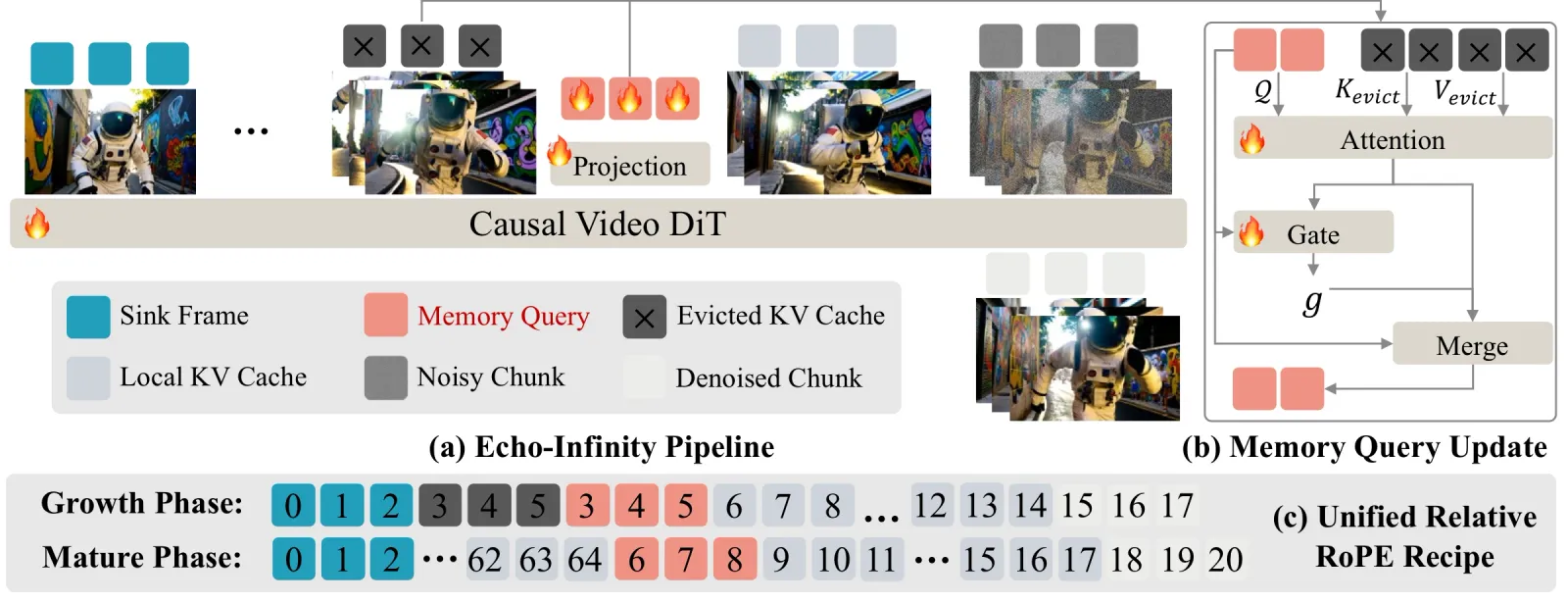
How the evolving memory works
Echo-Infinity takes its cue from human memory consolidation: keep an abstract gist, drop the raw detail. Instead of caching past frames directly, it maintains a small set of learnable Memory Query tokens. When a frame is evicted from the local attention window, its information is folded into these queries through attention and a gating mechanism, so the queries accumulate a compressed summary of everything seen so far. Crucially, the queries are trained end-to-end with the video diffusion transformer rather than fixed by a heuristic, so the model learns which history to filter, abstract, and compress. Because the memory is a fixed-size set of queries, computation per frame stays constant no matter how long the video runs, and the compression ratio is arbitrary by design.
The second piece is a Unified Relative RoPE Recipe. Naive AR rollout pushes positional indices past the maximum temporal RoPE id the base DiT was pretrained on, which causes extrapolation failure. Echo-Infinity anchors sink frames and keeps frame ids growing at most to the pretrained maximum, eliminating the finite-RoPE constraint without retraining the positional scheme from scratch.
Key results
- Real-time infinite rollout: 24-hour generation exceeding 1.3 million frames in real time, stated as the first such demonstration.
- Speed: 18.5 FPS on an H100, in the same range as competing memory methods (LongLive 20.7, MemFlow 18.7, Memorize-and-Generate 21.7) while sustaining quality far longer.
- Long video, VBench-Long: 85.61 total at 30 seconds and 82.01 at 240 seconds, with a 59.53 semantic score at the long horizon.
- Interactive 60s: 81.71 quality score and 34.10 CLIP score.
- Short video, VBench 5s: 85.35 total, 86.32 quality, 81.49 semantic, confirming the memory mechanism does not cost short-clip quality.
The honest read: the throughput is competitive but not the headline; rivals are within a few FPS. The differentiator is that Echo-Infinity holds quality across a 240-second clip and a 24-hour rollout where fixed-memory baselines degrade, because the memory is learned rather than scheduled.
Limits and open questions
The 24-hour and 1.3M-frame claims are demonstrations of stability and throughput, not proof of long-range semantic coherence — VBench measures per-clip quality, not whether the world stays consistent over an hour of story. The long-horizon semantic score (59.53 at 240s) is much lower than short-clip semantics (81.49 at 5s), so meaning still erodes even if visual quality holds. Speed parity with simpler KV-cache methods means the win is conditional: you adopt the learnable memory for sustained-rollout quality, not for raw FPS. The reported numbers are single-config benchmark results, and how the learned compression behaves on out-of-distribution scene changes or hard cuts over very long rollouts is not characterized here.
FAQ
What is Echo-Infinity?
Echo-Infinity is an autoregressive video diffusion framework that targets real-time infinite video generation by learning an evolving memory of past frames at constant per-frame cost, rather than curating history with fixed rules. It demonstrates 24-hour real-time rollouts over 1.3 million frames.
How does the learnable evolving memory differ from a KV cache?
A KV cache stores past frame keys and values directly and evicts them on a fixed schedule, losing whatever falls out of the window. Echo-Infinity instead folds evicted frames into learnable Memory Query tokens via attention and gating, so history is summarized rather than dropped, and the queries are trained end-to-end to decide what matters.
What is the Unified Relative RoPE Recipe?
It is a positional encoding scheme that anchors sink frames and caps how far frame ids grow, keeping them within the base DiT’s pretrained maximum temporal RoPE id. This prevents the extrapolation failure that occurs when AR rollout pushes positions past what the model was trained on.
How fast and how long can Echo-Infinity run?
It runs at 18.5 FPS on a single H100 and demonstrates 24-hour rollouts exceeding 1.3 million frames in real time, with per-frame compute held constant regardless of video length.
One line: learn what to remember instead of scheduling what to forget, and a video model can roll out for 24 hours without the drift that sinks fixed-memory methods. Read the original paper on arXiv.