AI Agents · LLM Reasoning · Efficient AI
StreamMA: Streaming Beats Waiting in Multi-Agent Reasoning
StreamMA pipes each reasoning step to the next agent the moment it is written, not after the full chain. Across 8 benchmarks it gains +7.3 pp on average (max +22.4 pp on HMMT 2026) and runs up to 26.9x faster.
Quick answer
StreamMA changes one thing about how multiple LLM agents talk to each other. Instead of agent A finishing its entire chain-of-thought and then handing the whole thing to agent B (the usual “generate-then-transfer” pattern), A streams each reasoning step downstream the instant it is produced. B starts working on A’s early steps while A is still thinking. That pipelining is the obvious win. It cuts end-to-end latency, up to 26.9x in the most parallel setting they test (64 agents, 64 steps each), hitting about 83% of the theoretical speedup bound.
The non-obvious win is accuracy. Across eight reasoning benchmarks, StreamMA beats both the serial multi-agent baseline and the single-agent baseline by +7.3 percentage points on average, with a +22.4 pp peak on HMMT 2026 using Claude Opus 4.6-high. The authors argue this is not a fluke. It is a direct consequence of where reasoning chains go wrong.
Why streaming partial chains makes agents smarter, not dumber
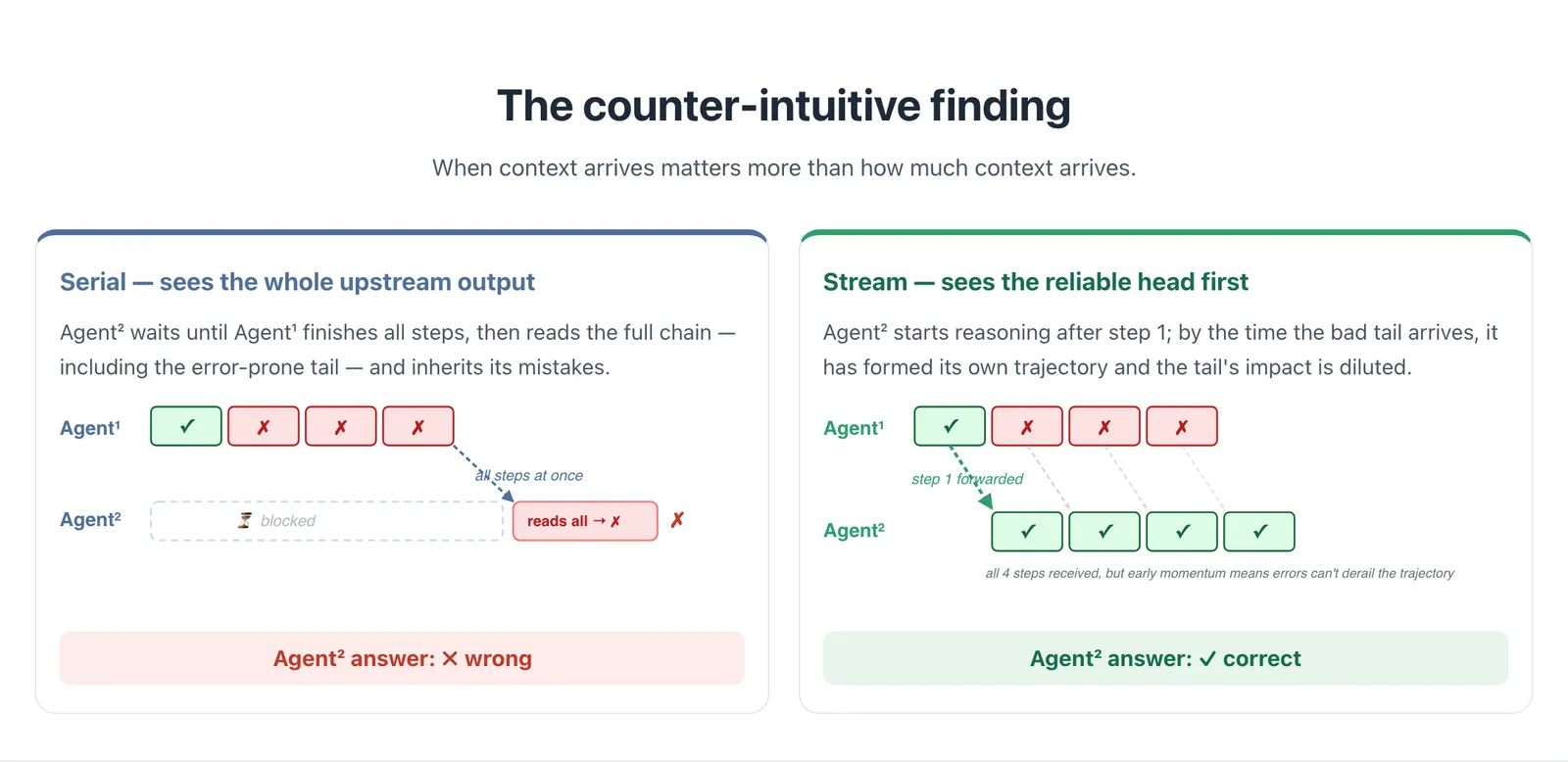
The counter-intuitive result is the headline. Normally you would expect that giving a downstream agent less of the upstream agent’s work (only the early steps, not the finished answer) would hurt it. StreamMA finds the opposite, and the explanation is sharp: multi-step reasoning quality is non-uniform. Early steps in a chain-of-thought are more reliable; later steps accumulate errors, drift, and over-thinking. A serial agent that waits for the complete upstream chain inherits that error-prone tail and gets misled by it.
A streaming agent sees the reliable head first and starts forming its own trajectory off it. By the time the bad tail arrives, the downstream agent already has momentum, so the late-step mistakes are diluted rather than copied. Speed and quality come from the same mechanism, so you are not trading one for the other. That is the cleanest way to read this paper: it reframes “how much context to pass between agents” as “when context arrives,” and shows timing dominates volume.
The theory: stream vs serial vs single, in closed form
What lifts this above an empirical trick is that the authors give the first closed-form joint analysis of three communication protocols: stream, serial, and single. From it they derive three things: an effectiveness ordering (which protocol is expected to be more accurate, and why), a speedup upper bound (how much faster streaming can be given pipeline depth and step count), and a cost ratio (token spend relative to the baselines).
The cost story is concrete. In their accounting, a Stream x4 configuration runs about $2.75 against $5.46 for a Serial x16 setup, roughly half the price at higher accuracy. They report streaming reaching better results at a lower cost regime rather than buying accuracy with more tokens. The speedup bound is what the 26.9x / 83%-of-bound number is measured against: streaming cannot beat the theoretical pipeline limit, and in practice it lands close to it.
The step-level scaling law
The last contribution is a new scaling knob. Multi-agent work usually scales by adding agents. StreamMA reports that scaling the number of reasoning steps per agent (S) while holding agent count fixed consistently improves both effectiveness and efficiency, which they call a “step-level scaling law.” It is described as orthogonal to and composable with agent-count scaling: you can push both dials together. If it holds up, this is a genuinely useful design lever, because steps are cheaper to add than whole agents and they feed the streaming pipeline naturally.
Key results
- +7.3 pp average accuracy gain over both the serial multi-agent and single-agent baselines, across all eight benchmarks.
- +22.4 pp peak gain on HMMT 2026 with Claude Opus 4.6-high, the largest single-benchmark jump.
- Up to 26.9x wall-clock speedup at the A=64, S=64 configuration, about 83% of the theoretical speedup bound.
- Stream x4 at ~$2.75 vs Serial x16 at ~$5.46: higher accuracy at roughly half the cost.
- Tested on 8 benchmarks (AIME25, AIME26, HMMT 2026, GPQA-D, HLE, and three LiveCodeBench splits LCB-G/E/T) spanning math, science, and code; two frontier LLMs (Claude Opus 4.6, GPT-5.4); three topologies (Chain, Tree, Graph).
- A step-level scaling law: more steps per agent improves both accuracy and efficiency, orthogonal to agent-count scaling.
Limits and open questions
The biggest caveat is generality of the accuracy claim. “Early steps are reliable, late steps drift” is plausibly true for the long-chain math/science/code reasoning these benchmarks measure. But that is exactly the regime where over-thinking is a known failure mode. On tasks where the conclusion lives in the last step (multi-hop synthesis, long planning where the payoff is at the end), feeding downstream agents the early head could discard the part that matters. The paper does not seem to cover that case.
Second, the headline gains lean on Claude Opus 4.6-high; how much of the +22.4 pp survives on weaker or cheaper models, where early steps are themselves shakier, is the natural follow-up. Third, the closed-form analysis necessarily makes assumptions about step reliability and independence. The elegance is real, but the ordering it proves is only as good as those assumptions. Anyone whose workload is short-chain or single-shot can skip this: streaming’s advantage is structurally tied to long, multi-step chains across multiple cooperating agents.
FAQ
What is StreamMA and how is it different from normal multi-agent reasoning?
StreamMA is a multi-agent reasoning system that streams each reasoning step to downstream agents as soon as it is generated, instead of the standard generate-then-transfer flow where an agent finishes its whole chain before passing it on. This pipelines adjacent agents, cutting latency. Surprisingly, it also improves accuracy by letting downstream agents work from reliable early steps rather than error-prone full chains.
How much faster and more accurate is StreamMA?
In the paper’s benchmarks StreamMA averages +7.3 percentage points over both serial and single-agent baselines, peaking at +22.4 pp on HMMT 2026 with Claude Opus 4.6-high, and delivers up to a 26.9x wall-clock speedup (about 83% of the theoretical bound) at 64 agents x 64 steps, at roughly half the token cost of a comparable serial setup.
What is the step-level scaling law in StreamMA?
It is the finding that increasing the number of reasoning steps per agent, while keeping the agent count fixed, consistently improves both effectiveness and efficiency. The authors present it as a new scaling dimension that is orthogonal to, and can be combined with, the usual approach of adding more agents.