AI Agents · Agent Memory · Fine-Tuning & Adaptation
LatentSkill: Bake Agent Skills Into LoRA Weights, Not the Prompt
A hypernetwork compiles a textual skill into a LoRA adapter in one forward pass. On ALFWorld, LatentSkill lifts success by 21.4 points (seen) with 64.1% fewer prefill tokens.
Quick answer
LatentSkill moves an LLM agent’s skill library out of the prompt and into the model weights. A pretrained Transformer “skill compiler” reads a textual skill document and emits a LoRA adapter in a single forward pass; that adapter is mounted while the agent acts, so the skill costs roughly zero context tokens at run time. On ALFWorld it raises task success by 21.4 points on the seen split (74.3% vs 52.9% for the in-context baseline) and 13.4 points on unseen (69.4% vs 56.0%), while using 64.1% fewer prefill tokens. On Search-QA it gains +3.0 exact-match points with a 72.2% cut in skill-token overhead.
The headline is not “LoRA beats prompting.” It is that you can generate a useful adapter from text on demand, without per-skill gradient training, and that the resulting weight-space skills behave like composable objects.
How the skill compiler works
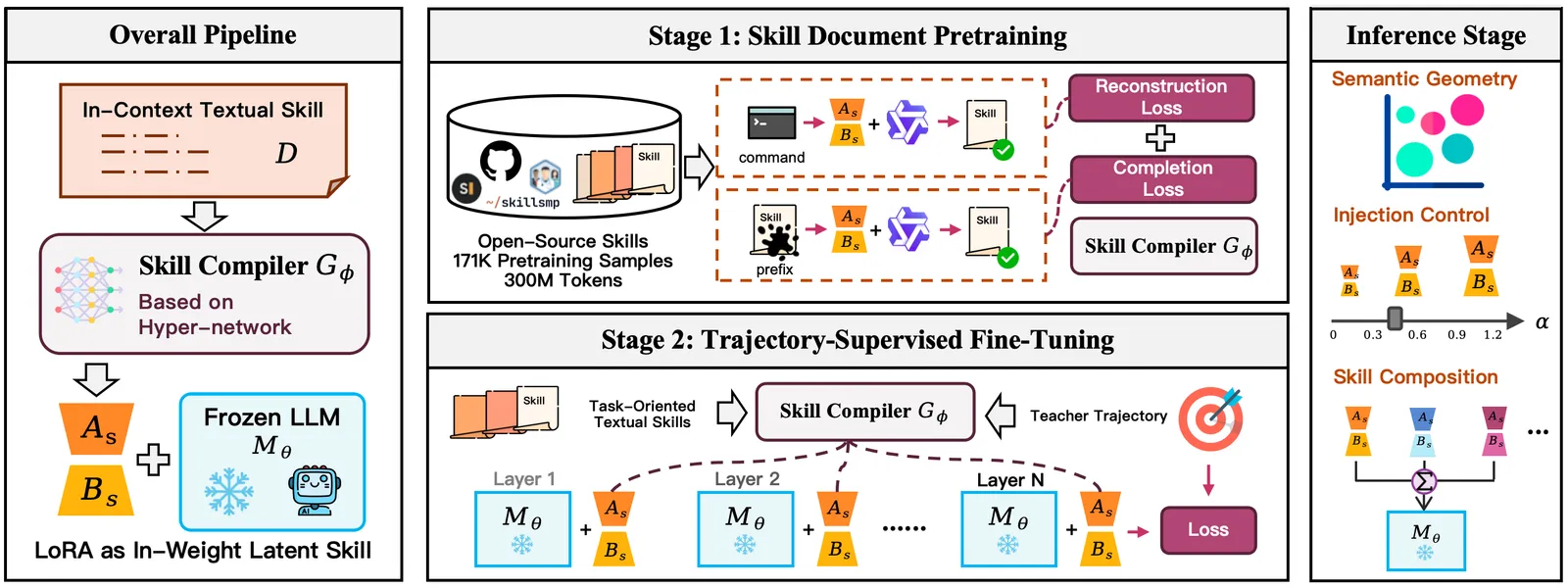
The core component is a hypernetwork G_φ that maps a skill document to LoRA weights. Training runs in two stages, then inference is cheap.
Stage 1, skill-document pretraining: the compiler is trained on roughly 171K GitHub skill documents (about 300M tokens) with reconstruction and completion objectives. The trick is that the generated adapter must let the base model reproduce or finish the skill text, so knowledge is forced to flow through the adapter rather than the prompt. This is what teaches G_φ to turn prose into weights at all.
Stage 2, trajectory-supervised fine-tuning: the compiler is tuned on 237 ALFWorld and 500 Search-QA trajectories. A single adapter is generated per skill document and kept mounted for the whole trajectory, which pushes the skill to stay behaviorally consistent across many steps instead of being re-interpreted token by token.
At inference, each skill compiles once into an adapter cache. Mounting applies a scaling coefficient α to control injection strength, and the backbone (Qwen3-8B here) runs as usual. Because the skill lives in weights, the context window is freed for the actual task and history.
Skills as composable weights
The more interesting claim is geometric. When the authors visualize generated LoRA adapters (MDS plots, Figure 3), semantically related skills cluster together and out-of-domain skills sit apart. The compiler has learned a structured skill space, not a lookup table.
That structure makes composition possible, but only the careful version works. The paper tests three merge strategies:
- Direct merging (add full LoRAs): fails, because shared components get over-amplified.
- Text merging (concatenate skill texts, then compile): fails, because the joined text is out-of-distribution and produces incoherent behavior.
- Component merging (decompose each skill into semantic subcomponents, compile separately, add aligned parts): works. Composing “Look + Pick” reaches 84.6% seen / 77.8% unseen on the relevant episodes.
So weight-space skill arithmetic is real, but it lives at the level of decomposed components, not whole adapters. That distinction is the part of the paper worth remembering.
Why this matters now
Agent frameworks increasingly stuff skill libraries, tool docs, and few-shot exemplars into the prompt, and that context tax compounds at every step of a long trajectory. LatentSkill is a clean argument that a chunk of that context is really parameters in disguise, and that you can amortize it by compiling once. The 64.1% prefill reduction on ALFWorld is the concrete payoff: cheaper, faster steps without losing the skill.
It also sidesteps the usual cost of per-skill fine-tuning. Because the hypernetwork generates adapters, adding a new skill is a forward pass over its document, not a training run. For teams maintaining a growing skill catalog, that is the practically appealing bit.
Key results
- ALFWorld seen: 74.3% success vs 52.9% in-context skill — +21.4 points.
- ALFWorld unseen: 69.4% vs 56.0% — +13.4 points, evidence the compiled skills generalize, not just memorize.
- Prefill tokens (ALFWorld): 64.1% fewer than the in-context baseline.
- Search-QA: 35.6% average exact match vs 32.6% (+3.0), with 72.2% skill-token reduction (0.31k vs 1.10k tokens).
- Composition: component merging of Look + Pick hits 84.6% seen / 77.8% unseen; naive direct and text merging both degrade.
- Injection coefficient α: follows an inverted-U; best values land around 0.5–0.8 and vary by task.
- Baselines beaten include Vanilla, Few-Shot, Reflexion, AdaPlanner (ALFWorld) and CoT, RAG, R1-Instruct (Search-QA).
Limits and open questions
The evidence base is narrow. Everything runs on one backbone (Qwen3-8B) with a fixed LoRA configuration, so it is unknown whether the compiler transfers across model families or scales. There are only two benchmarks, ALFWorld and Search-QA, and they exclude web browsing, software engineering, and multi-agent settings, which are exactly where skill libraries get large and messy.
The Search-QA gain (+3.0) is modest next to ALFWorld (+21.4), hinting the method helps most when skills are procedural and reusable rather than knowledge-retrieval-flavored. And the injection coefficient α is task-dependent with no global setting, a real tuning knob rather than a free win. Component merging requires hand-decomposing skills into subcomponents, so the elegant “skill arithmetic” still leans on manual structure.
Who should skip it: if your agent’s “skills” are mostly facts to retrieve, RAG is probably the better tool. LatentSkill earns its keep when the same procedural skill is invoked across many long trajectories and the prompt tax actually hurts.
FAQ
How does LatentSkill differ from RAG or in-context skill prompting?
RAG and in-context skills inject text into the prompt at run time, paying tokens on every step. LatentSkill compiles the skill into a LoRA adapter once and mounts it in the weights, so the skill costs near-zero context tokens during the trajectory. That yields 64.1% fewer prefill tokens on ALFWorld while improving success.
Does LatentSkill need to train a separate model for each new skill?
No. A pretrained hypernetwork generates the LoRA adapter from the skill’s text document in a single forward pass, so adding a skill is inference over its document rather than a fine-tuning run. The hypernetwork itself is trained once on ~171K skill documents plus a small set of trajectories.
Can LatentSkill combine multiple skills at once?
Yes, but only via component merging: decomposing skills into semantic subcomponents and adding aligned parts in weight space (e.g. Look + Pick reaching 84.6% seen). Naively adding full adapters or concatenating skill texts both fail.