Agent Memory · Multimodal Models · Reinforcement Learning
TaskMem: Teaching a Video Agent What Is Worth Remembering
TaskMem trains a multimodal agent to write its own memory with RL, lifting streaming-video QA accuracy to 67.9% on VideoMME and 45.4% on EgoLife, gains of 6.3 and 7.0 points over the Qwen3-VL-30B baseline.
Quick answer
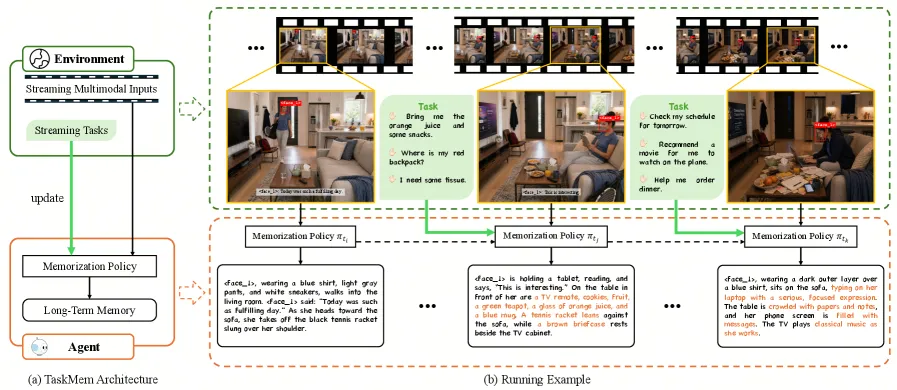
TaskMem treats memory writing as a policy the agent learns, not a fixed summarization rule. Instead of compressing every video segment the same way, the agent decides what is worth keeping based on the tasks it actually faces. The authors reformulate three benchmarks into streaming scenarios, where questions must be answered from the agent’s written memory rather than the raw video. On those, TaskMem reaches 67.9% accuracy on VideoMME, 45.4% on EgoLife, and 27.6% on EgoTempo, beating the Qwen3-VL-30B-A3B baseline by 6.3, 7.0, and 5.3 points respectively. The interesting part is not the headline gains. It is that the second training phase tunes only a 2,048-parameter adapter, leaving the 30B base model frozen.
The problem: memory is a write problem, not a read problem
Most long-term memory work for agents focuses on retrieval: given a good store, fetch the right fact. TaskMem argues the harder bottleneck is upstream. When an agent watches an unbounded stream of video, what should it even write down? Store too little and the answer is gone. Store everything and you drown in a combinatorial explosion of irrelevant detail, and the memory itself becomes too long to use.
The framing here is that memorization should be task-focused. The same five minutes of kitchen footage should produce different memory depending on whether the agent will later be asked about ingredient quantities or about where someone left their keys. A fixed captioner cannot do that because it does not know the downstream task distribution. TaskMem makes the memory-writing policy learnable so it can shift its focus toward the kinds of questions the environment actually asks.
How TaskMem’s two phases work
The agent models memory generation as a policy that, at each step, writes a memory chunk conditioned on a sliding window of the last k=5 video segments plus the recent prior memories. Training happens in two stages with different goals.
Phase One (pre-deployment) optimizes raw memory quality with reinforcement learning, using GSPO (Group Sequence Policy Optimization) over 326 long videos. The reward is multi-objective: format compliance, a soft length penalty, a quality term (judged by GPT-4o and Gemini-2.5-Flash on accuracy and non-redundancy), and a content-richness term scored by relative ranking within each rollout group. The paper calls these the fidelity constraints: the floor any usable memory must clear before task-shaping is even meaningful.
Phase Two (post-deployment) is the genuinely novel part. It inserts a lightweight adapter of just 2,048 parameters at transformer layer 22 and tunes only that adapter with DPO, using the Phase One model as the frozen reference. The trick is converting sparse, noisy task feedback into pairwise preference data through a task-relevance reward model, so the agent learns to bias its writing toward what the deployed tasks reward, without touching the base weights or needing dense supervision.
Key results
- VideoMME: 67.9% accuracy (P1+P2) versus 61.6% baseline and 64.4% after Phase One alone. Memory coverage rose to 79.3% and precision to 85.6%. So both phases help, and Phase Two does most of the heavy lifting on this benchmark.
- EgoLife: 45.4% accuracy versus 38.4% baseline, the largest absolute gain at +7.0 points, with precision climbing from 73.3% to 80.5%. Egocentric daily-life video is exactly the regime where indiscriminate memorization fails, so a task-focused policy pays off most here.
- EgoTempo: 27.6% accuracy versus 22.3% baseline (+5.3). Note the absolute numbers stay low across all methods. Temporal reasoning over egocentric streams is far from solved, and the paper concedes a GPT-5.2 reference slightly edges TaskMem on EgoTempo’s temporal questions despite TaskMem’s higher precision.
- Phase split matters: across all three, Phase One gives a modest bump (1–2 points) and Phase Two delivers the rest. That is strong evidence that task-relevance shaping, not just better generic summarization, is what moves the needle.
Why this is worth attention now
This lands as agents move from single-turn chat to long-horizon, continuously-observing roles: wearables, assistants watching a screen, robots logging a day. In that setting, a frozen captioner is a liability, and retraining a 30B model per deployment is absurd. TaskMem’s answer is to freeze the backbone and ship a 2K-parameter adapter that adapts memorization to the local task distribution. That is the kind of cheap, deployable knob that could actually survive contact with production. Whether the adapter idea generalizes beyond VQA is the open bet.
Limits and open questions
The paper has no explicit limitations section, which is its own tell. The evaluation is entirely VQA-style: answer a question from memory. It does not show the policy helping on planning, tool use, or action selection, which is where “agent memory” ultimately needs to prove itself. Phase Two also requires real task feedback from the deployment environment to build preference pairs. In a cold-start setting with no task signal, you are back to Phase One quality. The quality reward leans on GPT-4o and Gemini-2.5-Flash as judges, inheriting their biases and cost. And the absolute EgoTempo numbers (sub-30%) are a reminder that even the best version is far from reliable on temporal reasoning. Read this as a strong demonstration that what to memorize is learnable and cheap to adapt, not as a finished long-term-memory system.
FAQ
What is TaskMem and how is it different from RAG-style agent memory?
TaskMem is a framework that trains the memory-writing policy of a multimodal agent with reinforcement learning, rather than improving retrieval over a fixed store. RAG-style systems assume the memory already exists and focus on fetching; TaskMem focuses on deciding what to write down from a streaming video in the first place, shaped by the downstream task distribution.
What base model and benchmarks does TaskMem use?
It is built on Qwen3-VL-30B-A3B and evaluated on VideoMME, EgoLife, and EgoTempo, each reformulated into a streaming scenario where the agent must answer questions from its own generated memory rather than re-watching the raw video.
How much does TaskMem improve over the Qwen3-VL baseline?
Accuracy gains of 6.3 points on VideoMME (to 67.9%), 7.0 on EgoLife (to 45.4%), and 5.3 on EgoTempo (to 27.6%), with most of the gain coming from the Phase Two DPO adapter rather than the Phase One RL pre-training.