TaskMem:教视频智能体学会该记住什么
TaskMem 用强化学习训练多模态智能体自己写记忆,在流式视频问答上把 VideoMME 准确率提到 67.9%,比 Qwen3-VL-30B 基线高出 6.3 个点。
快速答案
TaskMem 把”写记忆”当成一个可学习的策略,而不是一条固定的摘要规则。智能体不再用同一种方式压缩每个视频片段,而是根据自己真正面对的任务来决定哪些内容值得保留。作者把三个基准改写成流式场景:问题只能依靠智能体写下的记忆来回答,而不能回看原始视频。在这些场景上,TaskMem 达到 VideoMME 67.9%、EgoLife 45.4%、EgoTempo 27.6% 的准确率,比 Qwen3-VL-30B-A3B 基线分别高出 6.3、7.0、5.3 个点。真正有意思的不是这些涨幅本身,而是第二阶段训练只调一个 2048 参数的适配器,30B 的主干模型全程冻结。
真正的瓶颈:记忆是”写”的问题,不是”读”的问题
大多数智能体长期记忆的工作都盯着检索:给定一个好的记忆库,把对的事实捞出来。TaskMem 的观点是,更难的瓶颈在上游。当智能体面对一段无尽的视频流时,它到底该写下什么?写得太少,答案就丢了;什么都写,就会陷入无关细节的组合爆炸,记忆本身也长得没法用。
这里的核心主张是记忆应当是任务聚焦的。同样五分钟的厨房视频,如果之后要问的是食材分量,和要问钥匙被放在哪里,应当产生不同的记忆。固定的字幕器做不到这一点,因为它根本不知道下游任务的分布长什么样。TaskMem 把写记忆的策略变成可学习的,于是它能把注意力偏向环境真正会问的那类问题。
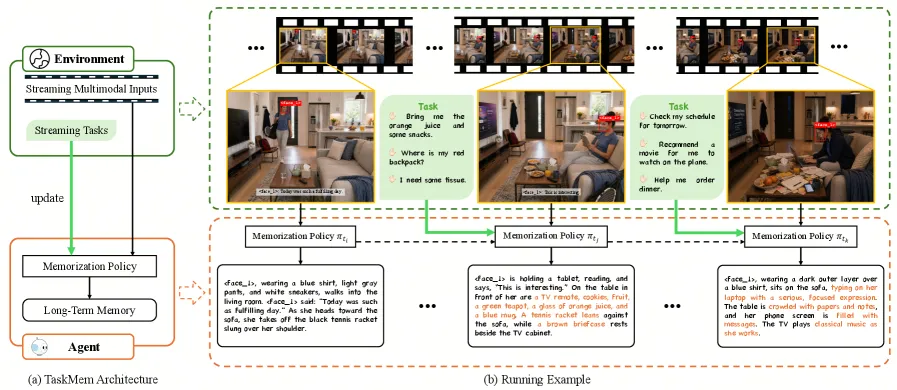
TaskMem 的两个阶段怎么跑
智能体把记忆生成建模成一个策略:在每一步,基于最近 k=5 个视频片段以及近期已有记忆组成的滑动窗口,写下一段记忆。训练分两个目标不同的阶段。
**第一阶段(部署前)**用强化学习优化原始记忆质量,在 326 段长视频上采用 GSPO(Group Sequence Policy Optimization)。奖励是多目标的:格式合规、长度软惩罚、质量项(由 GPT-4o 和 Gemini-2.5-Flash 从准确性与非冗余度打分),以及在每个 rollout 组内按相对排名计算的内容丰富度项。论文把这些称为保真约束:任何可用记忆在被任务塑形之前,都必须先跨过这道底线。
**第二阶段(部署后)**才是真正新颖的部分。它在 第 22 层 Transformer 处插入一个只有 2048 参数的轻量适配器,用 DPO 只微调这个适配器,并以第一阶段的模型作为冻结的参考策略。关键技巧是通过一个任务相关性奖励模型,把稀疏、带噪声的任务反馈转换成成对偏好数据。于是智能体学会把写作偏向部署任务所奖励的内容,既不动主干权重,也不需要稠密监督。
关键结果
- VideoMME 准确率 67.9%(P1+P2),对比基线 61.6%、仅第一阶段的 64.4%。记忆覆盖率升至 79.3%,精确率升至 85.6%。两个阶段都有用,但第二阶段在这个基准上挑了大梁。
- EgoLife 准确率 45.4%,对比基线 38.4%,是绝对涨幅最大的一项(+7.0),精确率从 73.3% 升到 80.5%。第一人称日常视频正是”无差别记忆”最容易翻车的场景,任务聚焦策略在这里收益最高。
- EgoTempo 准确率 27.6%,对比基线 22.3%(+5.3)。但要注意所有方法的绝对数值都偏低。第一人称视频流上的时序推理远未被解决,论文也承认在 EgoTempo 的时序题上,一个 GPT-5.2 参考模型尽管精确率更低,却略胜 TaskMem。
- 阶段拆分很关键:三个基准上,第一阶段只带来温和提升(1–2 个点),其余涨幅都由第二阶段贡献,这有力地说明真正推动指标的是任务相关性塑形,而非单纯更好的通用摘要。
为什么现在值得关注
它出现的时间点,正好是智能体从单轮对话走向长时程、持续观察角色的当口:可穿戴设备、盯着屏幕的助手、记录一整天的机器人。在这种场景里,一个冻结的字幕器是负担,而每次部署都重训一个 30B 模型则荒谬。TaskMem 的答案是冻结主干,只下发一个 2K 参数适配器来让记忆适应本地任务分布。这是那种便宜、可部署、可能真能在生产环境里活下来的旋钮。这个适配器思路能否推广到 VQA 之外,是悬而未决的赌注。
局限与存疑
论文没有显式的局限章节,这本身就说明了点什么。评测完全是 VQA 式的,也就是从记忆里答一个问题,因此没有展示该策略在规划、工具调用或动作选择上的帮助,而这恰恰是”智能体记忆”最终需要证明自己的地方。第二阶段还需要部署环境的真实任务反馈来构造偏好对;在没有任务信号的冷启动场景里,你就退回到第一阶段的质量。质量奖励依赖 GPT-4o 和 Gemini-2.5-Flash 当裁判,连带继承了它们的偏差与成本。而 EgoTempo 不到 30% 的绝对数值也提醒我们:即便是最好的版本,在时序推理上依然远谈不上可靠。请把它读作一个有力的论证:“该记住什么”是可学习且可廉价适配的,而不是一套完成品的长期记忆系统。
常见问题
TaskMem 是什么,它和 RAG 式智能体记忆有何不同?
TaskMem 是一个用强化学习训练多模态智能体写记忆策略的框架,而不是去改进对固定记忆库的检索。RAG 式系统假设记忆已经存在、专注于把它捞出来;TaskMem 关注的是首先该从流式视频里写下什么,并由下游任务分布来塑形。
TaskMem 用的是什么基座模型和基准?
它基于 Qwen3-VL-30B-A3B,在 VideoMME、EgoLife、EgoTempo 上评测,每个基准都被改写成流式场景:智能体必须依靠自己生成的记忆来答题,而不能回看原始视频。
TaskMem 相比 Qwen3-VL 基线提升了多少?
VideoMME 提升 6.3 个点(到 67.9%)、EgoLife 提升 7.0 个点(到 45.4%)、EgoTempo 提升 5.3 个点(到 27.6%),其中大部分涨幅来自第二阶段的 DPO 适配器,而非第一阶段的强化学习预训练。