When Vision Speaks for Sound: The Audio-Visual Clever Hans Effect
Top video models look like they hear audio but really guess it from the picture. This paper's THUD probes catch the cheat, and a 10K-sample fix lifts audio grounding by 28 points.
Quick answer
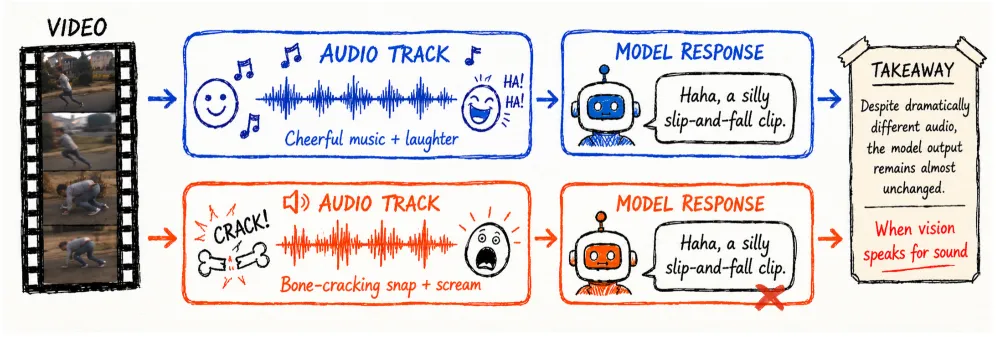
Multimodal video models that claim to “understand audio” mostly infer it from the video frames — an audio-visual Clever Hans effect. When this paper mutes the soundtrack, models still report hearing sound more than 63% of the time, because they are reading the scene rather than listening. The authors’ THUD framework exposes this with three counterfactual audio edits, and a 10K-sample two-stage fix raises average performance across the three probe dimensions by 28 percentage points while holding general video scores steady.
The Clever Hans problem in audio-video models
Clever Hans was a horse that “did arithmetic” by reading its trainer’s body language. The same trick shows up in omni-modal models: a model asked whether a door slammed can answer correctly by spotting the door closing on screen, never touching the audio stream. That makes standard audio-video benchmarks misleading — a high score can mean strong visual shortcutting, not real listening. The paper shows this is not a fringe failure: it appears in open models like Qwen3-Omni, MiniCPM-o, and Ming-flash-omni, and in proprietary systems including Gemini and GPT-class models.
How THUD breaks the shortcut
THUD (Temporal and Hallucination Unmasking Diagnostics) keeps the video fixed and edits only the audio, so any correct answer must come from actually processing sound. It uses three counterfactual interventions:
- Shift displaces the audio in time, testing whether the model notices audio-video desynchronization instead of assuming they always line up.
- Mute replaces the track with silence, testing whether the model detects the absence of sound rather than hallucinating it from the visuals.
- Swap substitutes a mismatched audio track, testing whether the model catches an inconsistency between what it sees and what it hears.
Because the visual evidence is unchanged across edits, a model that relies on it scores no better than chance on the audio question — which is exactly what the paper observes.
The two-stage fix
The repair is a training recipe, not a new architecture. Built on the Qwen3-Omni-30B backbone, it runs in two stages: supervised fine-tuning on data derived from the interventions, then Direct Preference Optimization that mixes counterfactual temporal preference pairs with general video preferences. The general-video mixing matters — it is what stops the model from over-fitting to the probe and collapsing on ordinary tasks. The whole thing uses only about 10K samples.
Key results
- Average audio-grounding gain: 28 percentage points across the three THUD dimensions after the 10K-sample recipe.
- Temporal synchronization (Shift): 34.3% to 83.1% — the largest single jump, showing the model learns to notice when audio and video are out of step.
- Out-of-distribution generalization: VGGSync rises from 36.8% to 56.4%, evidence the fix is not just memorizing the in-domain probe.
- Audio hallucination on muted clips exceeded 63% before the fix — a blunt measure of how much “listening” was actually scene-reading.
- General capability held steady: Video-MME 70.1%, LVBench 52.1%, WorldSense 50.3%, DailyOmni 67.9% — the audio repair did not tax broad video understanding.
The honest read: the Shift number is the headline, but it also flatters the result, because temporal alignment is the easiest of the three behaviors to teach with paired data. Mute and Swap — true presence detection and cross-modal consistency — are harder, and the 28-point average folds in all three.
Why it matters now
Omni-modal models are being marketed on audio understanding right now, and this paper argues that much of that capability may be a measurement artifact. THUD gives evaluators a cheap, mechanical way to separate genuine listening from visual guessing, and the fix shows the gap is closable with a small, targeted dataset rather than a from-scratch retrain. For anyone shipping or buying a video model that advertises audio reasoning, the muted-clip test alone is a fast sanity check worth running.
Limits and open questions
The fix is validated on a single backbone (Qwen3-Omni-30B), so whether the same 10K recipe transfers to other architectures or to the proprietary models the paper diagnoses is untested. THUD’s three edits are deliberately synthetic — shift, mute, swap — and real-world audio failures may be subtler than clean counterfactuals. The proprietary models are probed but not fixed, since their weights are closed. And a 28-point average across three dimensions can hide an uneven profile: the paper’s own numbers show temporal sync improving far more than the harder consistency behaviors, so “audio grounding solved” would overstate it.
FAQ
What is the audio-visual Clever Hans effect in When Vision Speaks for Sound?
It is the finding that video models appear to understand audio but actually infer it from the video frames. The paper’s evidence is that models report hearing sound on more than 63% of muted clips — they are reading the scene, not the soundtrack.
How does the THUD framework test audio grounding?
THUD holds the video fixed and edits only the audio with three counterfactuals — Shift (displace in time), Mute (replace with silence), and Swap (mismatched track). A model relying on visual shortcuts cannot answer these from the picture, so its score drops to near chance.
How much does the fix in When Vision Speaks for Sound improve audio understanding?
The 10K-sample two-stage recipe raises average performance across the three THUD dimensions by 28 percentage points, with temporal synchronization jumping from 34.3% to 83.1%, while general video benchmarks like Video-MME (70.1%) stay steady.
Which models show the Clever Hans effect?
Both open models (Qwen3-Omni, MiniCPM-o, Ming-flash-omni) and proprietary systems such as Gemini- and GPT-class models exhibit it. The paper fixes the effect only on the open Qwen3-Omni-30B backbone.
One line: a “good at audio” video model may just be a good lip-reader — mute the clip and find out. Read the original paper on arXiv.