World Models · Multimodal Models
WBench: A Multi-turn Benchmark for Interactive Video World Models
WBench scores interactive video world models on five axes — quality, setting, interaction, consistency, physics — across 289 cases and 1,058 turns, and finds no single model wins on all five.
Quick answer
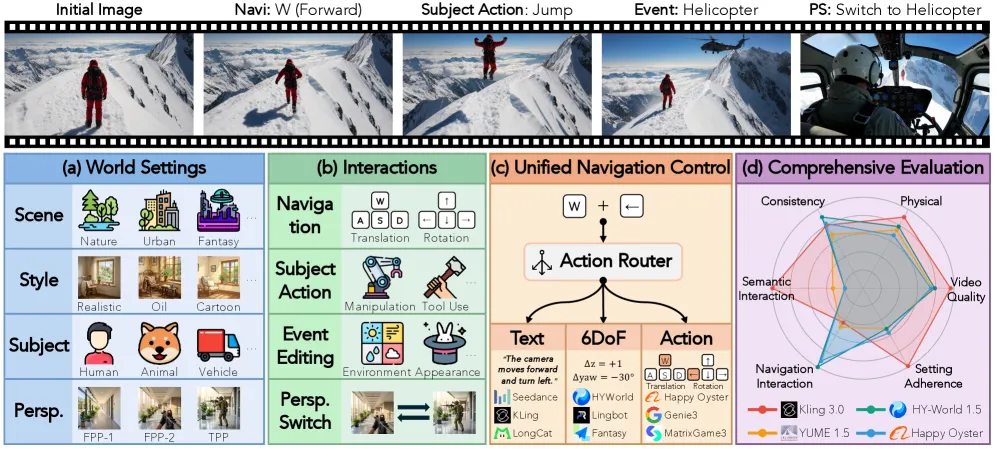
WBench is a multi-turn benchmark that probes interactive video world models across 289 test cases and 1,058 interaction turns, scoring every generation on five separate dimensions — video quality, setting adherence, interaction adherence, consistency, and physical compliance — with 22 automatic sub-metrics. After running 20 state-of-the-art models, the headline finding is blunt: no model leads on all five dimensions at once, so today’s “world models” are uneven rather than uniformly good.
Why single-turn benchmarks miss the point
A world model is supposed to be steered: you give it an instruction, it produces video, you react to that video, and you steer again. Most prior video-generation evaluation scores one clip from one prompt, which never tests whether the model holds its world together across a sequence of user interventions. WBench is built around that gap. It is explicitly multi-turn — the 1,058 turns spread over 289 cases mean roughly 3-4 interactions per case — so a model is judged on whether it survives sustained interaction, not on a single lucky frame.
The four ways you can interact
WBench defines four interaction types so the test covers more than “describe a scene.” A user can issue navigation (move through the environment), subject action (make an entity do something), event editing (change what happens in the scene), and perspective switching (move the camera viewpoint). This matters because the 20 evaluated systems are not all the same kind of model — the suite mixes text-driven, camera-controlled, and action-conditioned world models, and the four interaction types let one benchmark compare systems that are steered through very different control channels.
How the five dimensions are scored
Each turn is decomposed into 22 automatic sub-metrics that roll up into the five dimensions. Rather than lean on one large multimodal judge for everything, WBench pairs specialist vision models with multimodal models so each dimension is measured by an evaluator suited to it — e.g. dedicated vision components for consistency and physics, multimodal reasoning for whether an instruction was actually followed. The design choice that makes the benchmark credible is that these automatic metrics were validated against human judgment, not just asserted to correlate.
Key results
- Scale: 289 test cases and 1,058 interaction turns, scored on 5 dimensions via 22 automatic sub-metrics.
- Coverage: 20 state-of-the-art models evaluated, spanning text-driven, camera-controlled, and action-conditioned world models, across 4 interaction types (navigation, subject action, event editing, perspective switching).
- Human alignment: every automatic metric reaches a Spearman correlation of at least 0.94 with human judgment, and four aspects — event editing, subject action, perspective switching, and spatial consistency — hit perfect correlation.
- Top-line conclusion: no single model dominates all five dimensions; current systems are strong on some axes and weak on others, so a single leaderboard number would hide the real picture.
Why this benchmark matters now
Interactive video world models are being pitched as the substrate for game engines, robotics simulators, and agent training, and the marketing has outrun the measurement. WBench gives the field a per-dimension scorecard instead of a vibe, and the 0.94+ correlation with humans is the part that earns trust — a benchmark that disagrees with people is worse than no benchmark. The honest judgment here: the most useful output of WBench is not a winner, it is the demonstration that “world model quality” is not one number. A model that looks great on video quality can still violate physics or drift out of its setting, and buyers should ask which of the five axes they actually need.
Limits and open questions
The benchmark inherits the ceiling of its judges: automatic sub-metrics built on specialist and multimodal models can only be as discerning as those models, and 0.94 correlation still leaves disagreement with humans on harder cases. Physical compliance is the dimension most likely to be approximated rather than truly verified — checking whether a video obeys physics is far harder than checking whether an instruction was followed. The 289-case scale is reasonable for a curated multi-turn suite but small enough that a model could be tuned toward it. And because the field moves fast, a fixed set of 20 models is a snapshot; the lasting contribution is the protocol and the human-validated metrics, not the specific ranking.
FAQ
What does WBench measure?
WBench measures interactive video world models on five dimensions — video quality, setting adherence, interaction adherence, consistency, and physical compliance — using 22 automatic sub-metrics over 289 multi-turn test cases.
How is WBench different from normal video-generation benchmarks?
WBench is multi-turn and interactive. Instead of scoring one clip from one prompt, it runs 1,058 interaction turns across navigation, subject action, event editing, and perspective switching, so a model is judged on sustained steering rather than a single output.
Are WBench’s automatic scores trustworthy?
The authors validated WBench’s metrics against human judgment, reporting a Spearman correlation of at least 0.94 for every metric and perfect correlation on four aspects, including event editing and spatial consistency.
Which world model wins on WBench?
None outright. Across 20 evaluated models, WBench finds no single system dominates all five dimensions, so the right model depends on which axis — quality, physics, consistency, or instruction-following — matters most for your use case.
One line: WBench turns “is this world model good?” into five separate, human-validated questions, and the answer is that no model passes all five. Read the original paper on arXiv.