ARIS:用跨模型对抗多智能体做自主科研
ARIS 是开源自主科研框架,让 Claude 系执行者搭配 GPT 系审稿者互相攻击,专治「看似成功实则无依据」,含 65+ 技能与三阶段证据审计。
快速答案
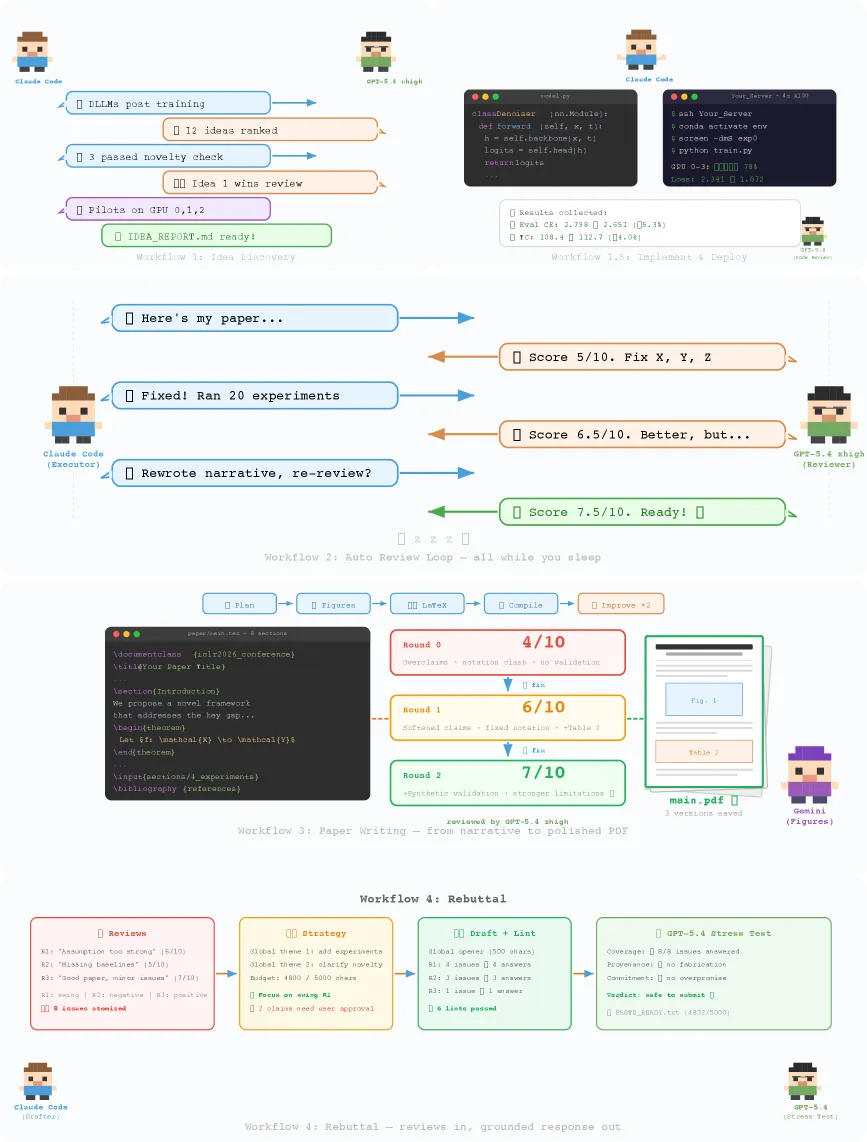
ARIS 是一套开源的自主科研框架,真正的核心只有一个:针对作者命名的失败模式「看似成功实则无依据」(plausible unsupported success)。长程智能体不报错、不崩溃,却悄悄给出从未核实过的结论。ARIS 的对策是把对抗式审稿设为默认:一个 Claude 系执行者模型,搭配一个来自不同模型家族的审稿者(GPT、Gemini、GLM、MiniMax、Kimi 或 DeepSeek),专门挑刺并逼它修改中间结果。系统自带 65 多个可复用的 Markdown 技能、五条端到端工作流,以及一套三阶段「证据到论点」审计。
ARIS 围着哪种失败模式设计
这里有意思的是它对「失败」的重新定义。多数智能体可靠性工作担心的是看得见的崩溃:循环卡死、工具报错、模型陷入死局。ARIS 认为真正危险的是反面。任务跑完了,论文看起来完工了,结论却没有依据。作者称之为「看似成功实则无依据」,它更难抓,恰恰因为表面上一切正常。一个伪造出干净结果的自主科研智能体,比一个高声失败的更糟,因为下游的人会信任那份精致的产物。ARIS 的一切都是为了让这种「安静的失败」变得难以抵达。
跨模型对抗协作
核心机制是:执行者和审稿者刻意来自不同模型家族。默认搭配是 Claude 执行者配 GPT 审稿者(通过 Codex MCP 和一个「Oracle」MCP 接入),审稿者的任务是攻击中间产物,而不是盖章放行。其赌注是:同一家族的两个模型共享盲点,会过于轻易地互相认可;而跨家族的批评者更可能揪出编造的引用或缺乏依据的跳跃。这个直觉是合理的,但论文把它当成默认配置来描述,而非用消融实验度量过。整套框架是被描述,而非被基准测试。
框架里到底有什么
ARIS 分三层。执行层装着技能:65 多个可复用 Markdown 文件,外加模型集成、一个持久化研究 wiki 和确定性的图表生成。编排层定义五条工作流:点子发现、实验桥接、自动审稿循环、论文写作、rebuttal,每条都有可调的「努力程度」档位。保障层是对抗思想落地的地方:一套三阶段「证据到论点」审计(实验完整性审计、结果到论点映射、论文论点审计)、一条五遍科学编辑流水线、数学证明核查、引用审计,以及对渲染出的 PDF 做视觉检查。它能跨执行器移植,论文称已在 Claude Code、Codex CLI、Cursor 上测试,另有三个完成适配。
关键结果
ARIS 是一篇系统与工具论文,不是基准论文,所以它的证据是描述性的,而非排行榜。它给出的具体数字:
- 执行层有 65 多个可复用 Markdown 技能,外加 30 多个社区贡献技能。
- 五条端到端工作流:点子发现、实验桥接、自动审稿循环、论文写作、rebuttal。
- 三阶段证据到论点审计 + 五遍科学编辑流水线。
- 一次示例性通宵运行跑了四轮审稿与修改,把审稿分从 5.0 提到 7.5(满分 10),并启动了 20 多个 GPU 实验。
- 在 三个执行平台(Claude Code、Codex CLI、Cursor)上测试,另适配三个;默认执行者/审稿者搭配可调用 六个以上审稿模型(GPT-5.4、Gemini、GLM、MiniMax、Kimi、DeepSeek)。
5.0 到 7.5 这个数字只是单次轶事性运行,且由系统自带的审稿模型打分,而非外部基准。当成演示看,别当成证明。
为什么现在重要
「睡觉时自动做科研」的智能体正当红,而大多数都在为「把任务做完」优化。ARIS 是少数把「做完但做错」当成头号敌人、并专门搭管线去抓它的工作。无论那个跨模型小技巧最终经不经得起推敲,它的框定才是值得带走的部分:长程智能体的真正风险是「自信满满却无依据」的输出,而非崩溃。而且框架开源,保障层可以单独复用。
局限与存疑
诚实的短板是证据。ARIS 描述了一套架构,只报告了一次示例性通宵运行;它没有提供受控研究来证明对抗审稿者相比单模型基线能可度量地减少无依据论点。那个 5.0 到 7.5 的招牌提升,是系统内部的 LLM 审稿者打的分,作为质量指标是循环论证。作者对天花板很坦白:「Aris 无法保证任何输出是正确的、新颖的或科学上成立的」。审计只降低坏输出的比例,并不能认证好输出。同时跑一个 Claude 执行者外加一个独立 GPT 系审稿者、横跨多条工作流也很贵,论文没量化这笔成本。指望拿到一键论文生成器的人该调低预期:这是一套带仪表、需人类在环的脚手架,不是自动驾驶。
常见问题
ARIS 解决什么问题?
ARIS 针对「看似成功实则无依据」:自主科研智能体跑完一轮、产出看起来完工的精致产物,但其论点其实从未被核实。它加了一层由审计和对抗审稿组成的保障层,让这种安静的失败更难发生。
ARIS 如何使用对抗协作?
ARIS 让执行者模型(默认 Claude 系)搭配一个来自不同模型家族的审稿者(GPT、Gemini、GLM、MiniMax、Kimi 或 DeepSeek)。审稿者批评中间结果并逼其修改,赌的是跨家族批评者能抓到同家族模型共享的盲点。
ARIS 开源吗?能在哪些工具上跑?
开源。ARIS 作为开源框架发布,已在三个执行平台测试:Claude Code、Codex CLI 和 Cursor,另有三个完成适配。它自带 65 多个 Markdown 技能,外加 30 多个社区贡献技能。
ARIS 能保证科研输出正确吗?
不能。作者明说 ARIS 无法保证任何输出是正确、新颖或科学上成立的。它的三阶段证据审计和五遍编辑能降低无依据论点的概率,但不能认证结果正确。
一句话:ARIS 赌的是,让一个跨家族审稿者去攻击你智能体的工作,是对抗「自信但错误」自主科研的最便宜防线。阅读 arXiv 原文。