Claw-SWE-Bench:编码智能体不能只看模型
Claw-SWE-Bench 用 350 个 issue 测 coding-agent harness,完整 adapter 让 OpenClaw Pass@1 升至 73.4%。
快速答案
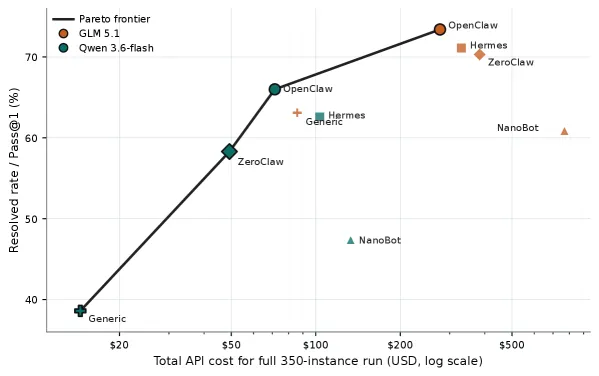
Claw-SWE-Bench 是一个 SWE-bench 风格的编码智能体 harness 评测,重点不是只比较底座模型。它包含 350 个 GitHub issue 修复实例,覆盖 8 种编程语言和 43 个仓库,并提供 80 题 Lite 子集用于低成本迭代。最醒目的数字是:在完整 benchmark 上,OpenClaw 使用最小 direct-diff adapter 时只有 19.1% Pass@1;换成完整 adapter 后,同一个 GLM 5.1 backbone 达到 73.4%。
它到底测什么
SWE-bench 要求干净 Docker workspace、补丁和预测协议。OpenClaw 这类通用智能体可以很会用工具,但它天然不满足 SWE-bench 的评分契约。Claw-SWE-Bench 加了 adapter protocol,让不同 agent harness 在同一 prompt、运行预算、workspace contract、patch extraction 和 evaluator 下比较。
这个区分很关键。如果智能体失败是因为 harness 抽不出正确 patch、workspace 管不好、停止时机不对,单独报模型分数就会误导读者。论文的核心主张是:harness design 本身就是编码智能体评测的一等变量。
Lite 子集为什么有用
完整 350 题评测很贵,因为每个样本都可能触发长时间 agent loop。Claw-SWE-Bench Lite 用 cost-aware、rank-aware 方法,从 17 个校准列中选出 80 个实例。它不是展示用小样本,目标是尽量保留排名、语言覆盖和成本结构,让团队能低成本调 adapter、prompt 和停止规则。
论文报告 Lite-80 的 full-run cost 约为 full-350 的 22.9%。在 17 个校准列上,full-350 的平均 Pass@1 为 0.639,Lite-80 为 0.643,差距约 0.4 个百分点。
关键结果
- 规模: 350 个 issue-resolution 实例,覆盖 8 种语言和 43 个仓库。
- Lite: 80 个实例,覆盖 34/43 个仓库,也就是完整仓库集合的 79%。
- Adapter 影响: 同一 GLM 5.1 backbone 下,OpenClaw 从 19.1% Pass@1 升到 73.4%。
- 模型轴: OpenClaw × 9 模型扫描中,模型选择带来 29.4 个百分点 Pass@1 差异。
- Harness 轴: 5 个 claw × 2 个模型扫描中,固定模型时 harness 选择带来 27.4 个百分点 Pass@1 差异。
- 成本: 准确率接近的系统可能总 API 成本差很多,所以论文把 cost、token 和 cache hit rate 与 Pass@1 一起报告。
最有用的结论是:harness 差异几乎可以达到模型差异的量级。隐藏 harness,只写模型名,很可能排错榜。
future-commit cleanup 说明了什么
论文还处理了 future-commit 可见性问题。SWE 风格任务里,智能体有时可能从仓库历史中看到 issue 之后的提交线索。清理后,9 个 OpenClaw 模型 run 的 Pass@1 都没有上升;最大下降来自 Claude Opus 4.7,从 84.7% 降到 76.7%,下降 8.0 个百分点。
这说明污染处理会影响排名,也说明读者应优先看 cleanup 后的数字。
局限与存疑
主要实验多为单次聚合结果,小幅差异不应被解读成稳定优劣。Claw sweep 覆盖 5 个 harness 和 2 个模型,足以证明 harness 很重要,但还不足以拆清模型家族、工具循环、parser、停止规则和成本之间的全部交互。成本数字也受 provider 定价和 cache accounting 影响。
更大的问题是:这种 model-harness 不可分现象是否同样出现在浏览器智能体、桌面智能体和科研智能体中? Claw-SWE-Bench 回答的是 SWE 风格编码任务,不是所有 agent 场景。
常见问题
Claw-SWE-Bench 是什么?
Claw-SWE-Bench 是一个多语言 SWE-bench 风格 benchmark 和 adapter protocol,用于在真实 GitHub issue 修复任务上评测编码智能体 harness。
Claw-SWE-Bench 有多大?
完整 benchmark 有 350 个实例,覆盖 8 种编程语言和 43 个仓库。Lite 子集有 80 个实例,用于低成本验证。
为什么 OpenClaw 会从 19.1% 升到 73.4% Pass@1?
19.1% 使用的是最小 direct-diff adapter,73.4% 使用完整 adapter,底座同为 GLM 5.1。这个差距说明 adapter 和 harness 设计会强烈影响编码智能体成绩。
Claw-SWE-Bench Lite 能替代完整 benchmark 吗?
不能。Lite-80 适合筛选、调试和回归检查。它把成本降到 full-350 的约 22.9%,并在校准研究中较好保持平均 Pass@1。
Claw-SWE-Bench 最大局限是什么?
当前结果主要是有限 harness/model 扫描上的单次聚合。要把几个百分点的 Pass@1 差异当作稳定结论,还需要更宽的复现实验。
一句话:Claw-SWE-Bench 的价值在于让编码智能体 harness 不再是被模型名遮住的隐形工程。阅读 arXiv 原文。