Harness-1:把搜索智能体的记账活儿搬出策略
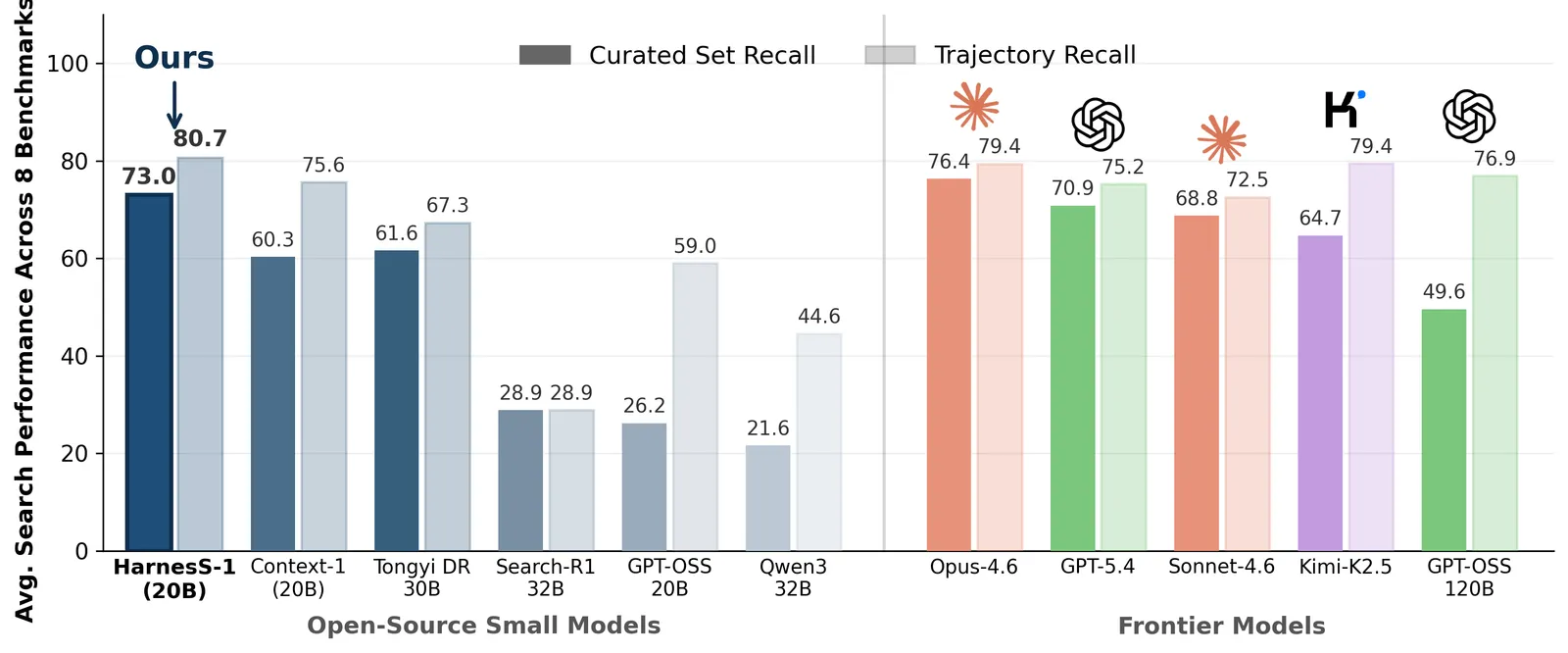
Harness-1 是个 20B 的 RL 搜索智能体,把工作记忆交给环境维护,平均策展召回 0.730,比最强开源子智能体高 11.4 分。
快速答案
Harness-1 是一个用强化学习训练的 20B 检索子智能体,但真正的看点不是模型大小,而是它不让模型做什么。作者把例行的状态管理(记录候选、给证据去重、记下哪些主张已核验、判断哪些内容塞得进上下文)从策略里剥离出去,塞进外围的 harness(智能体运行所处的环境侧脚手架)。策略只保留语义判断:搜什么、留什么、核验什么、什么时候停。
回报是实打实测出来的。在覆盖网页、金融、专利、多跳问答的八个检索基准上,Harness-1 拿到 0.730 的平均策展召回(curated recall),比最强的开源搜索子智能体高 11.4 分,并能与体量大得多的前沿模型搜索器掰手腕。增益最大的地方出现在留出的迁移基准上,这才是最关键的结果:说明它学到的是一种能泛化的搜索能力,而不是对基准的死记硬背。
“状态外置的 harness” 到底指什么
典型的搜索智能体被训练成一个在不断增长的对话记录上做决策的策略。每一步,同一个网络要同时干两件事:做真正难的语义决策(用哪个查询、选哪篇文档),还要记住那些枯燥的事:哪些约束还没满足、哪些主张已核验过、检索回来的五十段里哪几段值得留。论文的论点是:用 RL 去学这些枯燥活儿太浪费了。记账是可恢复的,环境完全可以确定性、可靠地维护它,逼着梯度下降从稀疏奖励里重新学一遍只会徒增方差。
于是 Harness-1 的 harness 在环境侧维护工作记忆:一个候选池、一个带重要性标签的策展集、紧凑的证据链接、核验记录、压缩并去重后的观测,以及预算感知的上下文渲染(在给定 token 预算下到底给模型看什么)。模型发出语义动作,harness 更新状态并渲染出下一帧视图。这是把系统设计里的”关注点分离”原则搬到智能体训练上的一招干净利落的操作。
强化学习如何配合这种拆分
一旦记账活儿交给了环境,奖励就能瞄准你真正在乎的目标:智能体有没有把对的证据攒齐?论文报告的指标是策展召回(金标准支撑证据中有多大比例最终落进了智能体的策展集),而不是只看最终答案准确率。这是有意为之。对于一个输出会喂给下游阅读器或规划器的检索子智能体来说,把对的证据召回才是诚实的目标;答案准确率会把检索质量和阅读器的推理能力混为一谈。
用这个信号、在有状态的 harness 里训练一个 20B 模型,正是迁移能力的来源。作者对泛化的说法把握得很谨慎:在显式搜索状态上做 RL,能产出在训练域之外依然站得住的检索策略,这恰好与”RL 智能体会过拟合训练环境”的常见担忧相反。
为什么是现在
搜索与”深度研究”智能体是 2026 年声量最大的一类智能体,多数已发表系统都在用越来越大的策略去追端到端答案准确率。Harness-1 是个有用的对照:一个 20B 模型之所以能与前沿规模的搜索器相提并论,是因为它把参数花在判断上,而不是花在记忆上。如果结论站得住,那么对所有做检索智能体的人来说,实用启示是:审一审你的策略到底背了多少”可恢复的状态”,然后把它们搬出去。
关键结果
- 平均策展召回 0.730,覆盖八个检索基准(网页、金融、专利、多跳问答)。
- 比最强开源搜索子智能体高 11.4 分,这是核心对比。
- 仅 20B 参数即与体量大得多的前沿模型搜索器掰手腕,体现了规模效率。
- 增益最大在留出的迁移基准上,这是 harness 教会了可泛化搜索能力、而非基准专属技巧的证据。
- 主指标是策展召回(对的证据有没有进策展集),而非仅看最终答案,这对检索子智能体而言更合适。
局限与存疑
诚实的保留意见集中在范围与披露上。其一,策展召回是检索侧指标:它衡量好证据有没有被攒齐,而非下游模型据此能否答对。高召回的子智能体仍可能喂给一个弱阅读器,所以光凭这些数字不能保证端到端收益。其二,“与大得多的搜索器相当”是个偏软的说法:摘要没钉死是哪些前沿模型、差多少,所以在读完逐基准表格前,对”打平”只能当作方向性结论。其三,harness 本身是手工设计的:候选池、重要性标签、去重、预算渲染都是设计选择,论文的增益可能部分来自调得好的脚手架而非 RL 本身。一个把 harness 贡献和策略贡献拆开的消融,是怀疑型读者该找的东西。最后,搭建并维护一个有状态的 harness 是实打实的工程开销,纯对话记录式的策略本可避开。
谁可以跳过:如果你只需要单一领域的一次性 RAG 检索器,这套 harness 机制属于杀鸡用牛刀。它的回报出现在多跳、多约束、重迁移的搜索场景里。
常见问题
Harness-1 和普通的 RL 搜索智能体差在哪?
普通搜索智能体把语义决策和例行记账揉进同一个策略里。Harness-1 把记账活儿(候选池、去重、核验记录、预算感知上下文)外置到环境侧的 harness,于是 RL 只优化语义决策:搜什么、留什么、核验什么、何时停。
Harness-1 的 0.730 策展召回放在大背景里算什么水平?
这是八个检索基准上的平均值,比最强开源搜索子智能体高 11.4 分,且仅 20B 参数就能与大得多的前沿模型搜索器相当。最强增益出现在留出的迁移基准上。
我已经有 RAG 管线了,还要不要用 Harness-1?
只有当你的任务是硬搜索(多跳、多约束或跨域)才值得。对单一领域的一次性检索,这套有状态 harness 的工程量超出你的需要;它的优势在迁移,以及跨多步攒齐策展证据。