DRPO:重新思考 LLM RL 中的散度正则
DRPO 把 DPPO 的硬散度 mask 换成平滑优势加权二次正则,保留 Binary-TV 信任域但梯度权重有界,在 BF16 和 FP8 下比 GRPO、SPO、DPPO 训得更稳。
快速答案
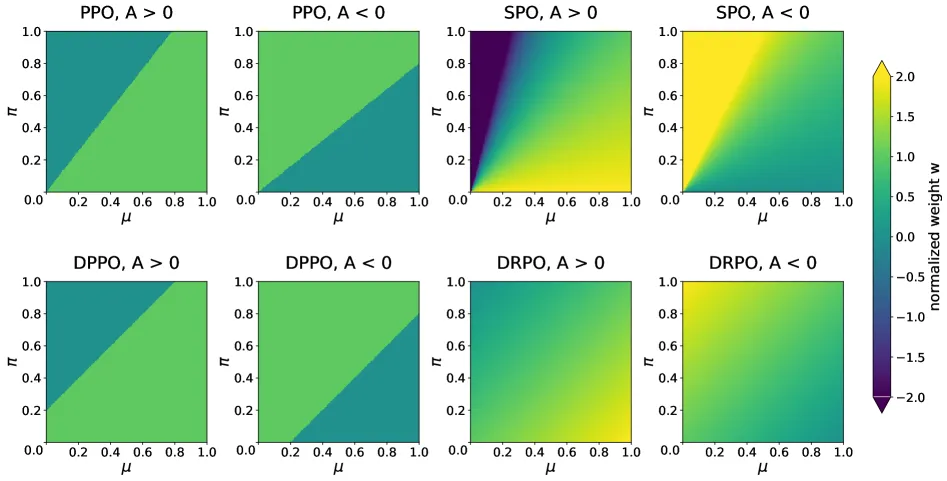
DRPO 是面向 LLM 的 RL 微调目标,把 DPPO 的硬散度 mask 换成平滑的优势加权二次正则。它保留了 DPPO 的 Binary-TV 信任域,边界由采样 token 的绝对概率偏移定义,但给出的是连续梯度权重,而非开关式截断。当更新偏离行为策略时,权重在边界处衰减到零,越过边界后转为修正方向;当更新朝行为策略靠回时,权重被放大。因为权重跟的是绝对概率偏移,即使在罕见 token 上也保持有界,而 SPO 基于比值的权重在这里会爆掉。论文报告,DRPO 在六个训练设置下都达到或超过 GRPO、SPO、DPPO 以及无正则 surrogate 的最好精度,在 FP8 低精度训练不稳时尤其有用。
问题:比值裁剪是糟糕的散度代理
LLM RL 通常是 off-policy。rollout 来自推理引擎,它的数值行为和训练引擎不同,轨迹又被切成多个 mini-batch,所以被更新的策略并不是产生数据的那个。PPO 和 GRPO 用逐 token 重要性比的裁剪来控制这种漂移。论文沿用 DPPO 和 Qi 等人的论点:在长尾词表里,重要性比是分布偏移的弱代理。在罕见 token 上,一点点绝对概率变化就会带来很大的比值变化,所以基于比值的信任域在尾部对噪声过度反应,在真正要紧处又反应不足。
DPPO 已经修了代理这一层:它把比值裁剪换成散度 mask,约束采样 token 的 Binary-TV 偏移,也就是当前策略和行为策略在该 token 上塌成伯努利后的绝对概率差。DRPO 保留这套几何,接着打下一个问题:DPPO 仍然用硬 mask。
硬 mask 错在哪,平滑正则修了什么
DPPO 的 mask 在 token 朝有害方向越过信任域边界后,把它的梯度清零。这让训练在边界附近很脆:散度估计稍有变化,token 就从满梯度跳到零。越过边界后也没有任何信号告诉策略该退回来。
DRPO 借了 SPO 的思路:用平滑二次惩罚而非不连续截断来约束同一条边界。结果是一个逐 token 梯度权重,随概率偏移的大小和方向连续变化。边界内,偏移逼近阈值时梯度被衰减。边界上权重为零,在相同阈值下与 DPPO 的稳定点重合。边界外权重变负,梯度反向,把策略拉回来。当更新朝行为策略靠回时,权重被放大而不是被压制。
相对 SPO 的新意在分母。SPO 的惩罚是优势加权的 Pearson 卡方,把每个平方偏移除以行为概率,于是被低概率尾部主导。DRPO 直接惩罚绝对概率偏移,是优势加权的 L2 平方距离,对当前策略和行为策略对称。因为 Binary-TV 落在 [0,1],DRPO 的梯度权重处处有界,方差至多四分之一。SPO 的权重则沿低概率轴无界增长。
为什么长尾要紧
这里的尾部不是可忽略的零头。图 2 报告,在 Qwen3-30B-A3B-Base 上,行为概率小于等于 0.01 的 token 占全部采样 token 的 7.8%。在这些 token 上,一点绝对偏移就带来很大的比值变化,于是 SPO 的比值权重可能主导梯度,而它对真实分布偏移的贡献很小。DRPO 的有界权重正是冲着这个区间来的。
关键结果
- 六个设置,全部稳定: 在 Qwen3-4B-Base、Qwen3-30B-A3B-Base(BF16、仅 rollout FP8、FP8-E2E)、Qwen3.5-35B-A3B-Base 和 DeepSeek-R1-Distill-Qwen-1.5B 上,DRPO 的 AIME24/AIME25 精度都达到或超过每个基线的最好值。
- 比值方法在 FP8 下崩溃: GRPO 和 SPO 在低精度设置里常常没到合理精度就崩,因为 FP8 加 MoE 架构放大了训练与推理的数值失配。
- 硬 mask 落后于平滑: DPPO 在 Qwen3-30B-A3B-Base 上训得稳,但收敛更慢、终值更低,这是论文支持平滑信号胜过脆性截断的证据。
- 信任域仍然必要: 无正则 surrogate 在六个设置里有三个掉点,Qwen3-4B-Base 上最猛,精度从 0.25 跌到 0.17。
- 修正信号扛起了收益: Mask-DRPO 在边界内用 DPPO 梯度、边界外才用 DRPO 梯度,效果与完整 DRPO 相当。可见大部分收益来自边界外的平滑修正,而非重塑边界内的梯度。
- 优势加权是承重项: 从 SPO 和 DRPO 里去掉绝对优势因子,都会稳定地掉点并破坏训练稳定性,因为这个因子让信任域边界不随奖励尺度变动。
局限与存疑
主指标是 AIME24/AIME25 平均精度,在正文里以图 3 的曲线汇总,没有逐设置的数值表,所以相对 DPPO 的领先是用达到或超过来描述,而非一个确定的差距数字。论文没有算力或墙钟核算,效率说法只靠图里收敛更快。基准全是数学题,用规则验证,跑在约 13K 的 DAPO 过滤子集上,所以对代码、智能体或开放式 RLHF 任务的泛化没有验证。DRPO 和 DPPO 共用一个阈值以做对等边界比较,但 DRPO 自己引入了正则阈值(设为 12.5),其敏感性被放到附录。最稳妥的说法是:它在难精度区间赢在稳定性和收敛,而不是在已经很强的 RL 配方上做大幅精度跃升。
对开发者的判断
如果你在 FP8 或 MoE 模型上跑 LLM RL,看到 GRPO 或 SPO 崩,DRPO 试起来很便宜:它只改逐 token 梯度权重,不需要新的 rollout 管线。要内化的机制是这个梯度视角。一个在 KL 或 TV 目标上看着没问题的正则,梯度仍可能诱导出基于比值的几何,而正是这套几何会在尾部爆掉。评判一个正则,看它产生的逐 token 权重,而不是目标上挂的散度名字。如果你已经在 BF16、稠密模型上训,从不遇到不稳定,那收益就小。
常见问题
DRPO(散度正则策略优化)是什么方法?
DRPO 是来自腾讯混元、UIUC 和 NUS 的 LLM RL 微调目标,随 UniRL 仓库发布。它把 DPPO 的硬散度 mask 换成对采样 token 绝对概率偏移的平滑优势加权二次正则。它保留 DPPO 的 Binary-TV 信任域,但产生有界、连续的梯度权重:边界内衰减更新,边界外修正更新。
DRPO 的平滑正则和 DPPO 的硬 mask 梯度有什么区别?
DPPO 在 token 朝有害方向越过信任域边界后把它的梯度清零,边界附近很脆,边界外也没信号。DRPO 用连续权重替掉这个截断:边界处衰减到零,边界外反向给出修正信号,朝行为策略靠回的更新被放大。Mask-DRPO 消融表明,收益主要来自边界外的这个修正信号。
在 DRPO 看来,为什么基于比值的裁剪是糟糕的分布偏移代理?
在长尾的 LLM 词表里,罕见 token 上一点点绝对概率变化会带来很大的重要性比变化,于是基于比值的信任域对尾部噪声过度反应。论文测得 7.8% 的采样 token 行为概率小于等于 0.01,在这里 SPO 的比值权重(1 除以 mu)可能主导梯度。DRPO 改为惩罚绝对概率偏移,它落在 [0,1],方差至多四分之一。
从结果看,DRPO 是提升精度还是只提升训练稳定性?
主要是稳定性和收敛。最清楚的赢面是 GRPO 和 SPO 在 FP8 下崩,而 DRPO 还能训;DPPO 收敛更慢、终值更低。最终 AIME24/AIME25 精度是用六个设置下达到或超过基线来报告的,不是一个固定的数值跃升,而且没有算力核算,所以把贡献读成更稳健的信任域,而非能力跃升。
一句话:DRPO 把 DPPO 的开关式散度 mask 变成平滑、有界的梯度权重,在长尾和 FP8 下换来更稳的 LLM RL,收益体现为收敛更快而非一个确定的精度差。阅读 arXiv 原文。