MatterGen 解读:用扩散模型做材料逆向设计
MatterGen 是按目标性质生成无机晶体的扩散模型——它唯一真正合成出来的 TaCr2O6,实测刚度与 200 GPa 目标相差约 20%。
快速答案
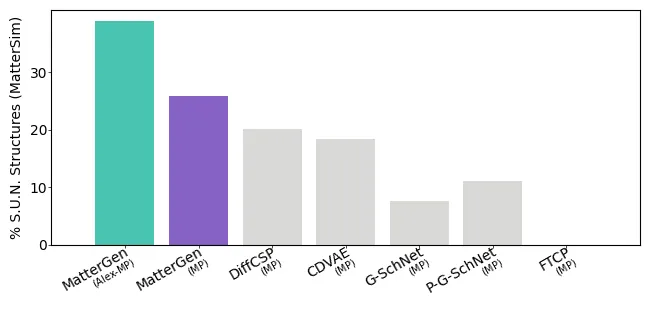
MatterGen 是一个扩散模型,它从想要的性质反推出新的无机晶体,而不是在已知候选清单里筛选。它同时对三样东西做去噪——原子种类、原子坐标和周期性晶格——因此生成的是一个完整的周期性晶体结构,而不是一个分子。微软用来自 Materials Project 和 Alexandria 的 608,000 个稳定结构训练它,最有说服力的测试很具体:要求体模量高于 400 GPa 的材料时,它在 180 次 DFT 验证的预算内产出了 106 个稳定、独特、全新的结构,而参考数据集里这类材料只有 2 个。论文 2025 年 1 月发表于 Nature,代码以 MIT 协议开源。
筛选 vs. 生成:真正的转变
找一个具备性质 X 的材料,标准做法是虚拟筛选:拿一个已知化合物数据库,逐个算 X,留下胜者。天花板就是这个数据库——你只能发现别人已经列出来的东西。MatterGen 把这个过程反了过来:你先指定性质目标,模型在该条件下采样晶体,取材于整张元素周期表的组合空间,而不是一份目录。
这种”反演”正是它的贡献,而 400 GPa 那个结果是最干净的证据。参考数据集里只有 2 个体模量超过 400 GPa 的超硬材料;MatterGen 给出了 250 多个候选,经 DFT 验证后有 106 个通过了”稳定-独特-全新”的门槛。筛选根本无法返回清单里不存在的东西。
扩散过程如何为晶体量身定制
晶体不是一团点云,它是无限的周期性堆叠,所以现成的分子扩散模型直接用会崩。MatterGen 跑三个互相耦合、针对晶体结构定制的”加噪-去噪”过程:一个对原子种类的离散扩散、一个尊重周期性边界(可环绕)的坐标扩散、一个针对晶胞形状的晶格扩散。一个学习得到的打分网络把三者一起逆转,模型被训练得能把样本驰豫到局部能量最小值附近。
正是这种”几何感知”让下一节里”贴近最小值”和”高新颖度”的数字成为可能:一个忽视周期性的生成器,产出的结构会被 DFT 拖很远才能到达任何稳定构型,白白浪费算力预算。把晶格当作一等变量,正是”值得验证的提议”和”噪声”之间的分界。
关键结果
最关键的数字集中在三处。**按需的高刚度:**在 400 GPa 体模量条件下,MatterGen 在 180 次 DFT 验证内给出 250 多个候选、106 个稳定-独特-全新的结构,而参考数据集里只有 2 个。**几何保真度:**生成结构相对其驰豫最小值的平均位移约 0.021 埃,比此前的生成模型贴近能量最小值约一个数量级。**真正的新颖性:**基础模型的稳定-独特-全新(S.U.N.)比例为 38.57%,而条件生成在充分探索、部分探索、未探索的化学体系上分别为 83% / 65% / 49%。最后这条梯度才是诚实的标题——模型在化学已被充分摸清的地方最可靠。
用性质适配器来引导
你不需要为每个设计目标重训 MatterGen。基础模型在某个带标签的性质上用轻量适配器模块微调,再在采样时施加条件。微软在力学(体模量)、电子(带隙)、磁密度,以及化学/对称性目标上都做了演示,甚至还有一个把”高磁密度”与”低供应链风险元素”结合起来的多性质目标。
上面那条条件 S.U.N. 梯度的实际含义是:MatterGen 恰恰在你最不需要它的地方最可靠,而当你推进到真正新的化学领域时,命中率大致腰斩。多性质那个案例才是更有意思的演示——同时叠加两个适配器,正是一份真实设计需求(“强磁体、无稀土瓶颈”)的样子,而且它比单性质目标更难靠”检索”蒙混过去。
让它落地的那一个实验
一篇声称发现新材料的计算论文很廉价;MatterGen 最重要的一段是合成。在 200 GPa 体模量的条件下,它提出了 TaCr2O6,深圳先进技术研究院的合作者真的把它做了出来。合成的晶体在 Ta 和 Cr 之间表现出组分无序(实验室做出来的是 MatterGen 所画有序结构的无序变体),实测体模量落在 200 GPa 目标的约 20% 误差内。一个化合物当然不足以证明这是一台”发现引擎”,但它把结论从”看似合理的结构”变成了”一个一阶达标的真实材料”。
局限与存疑
发布后最尖锐的批评来自一篇《Materials Horizons》的分析:它认为 MatterGen 经常重新预测训练数据里已有的化合物,质疑其中究竟有多少是真正新的、又有多少是被”检索”出来的。S.U.N. 指标正是为过滤这种情况而设计的,但这场争论真实存在、尚无定论。除了新颖性,整条流水线仍依赖 DFT 来验证每一个候选,所以”按需生成”受限于你能负担多少次密度泛函计算——刚度案例里 180 次计算换来 106 个命中,高效但不免费。可合成性同样没有保证:一个结构可以 DFT 稳定却仍难以被制造出来,而那唯一成功的 TaCr2O6 也是以无序态、而非精确目标的形态被做出来的。请把 MatterGen 当作一个能压缩搜索空间的强提议者,而不是一个直接交给你成品材料的神谕。
常见问题
MatterGen 到底生成什么?
MatterGen 在目标性质的条件下,生成完整的无机晶体结构——原子种类、它们的三维坐标,以及周期性晶胞晶格。与分子生成器不同,它的扩散过程是围绕晶体周期性和对称性构建的,因此输出的是可直接做 DFT 驰豫的完整周期性结构,而不是孤立分子。
MatterGen 和材料筛选有什么不同?
筛选只对数据库里已有的化合物算性质并留下最好的,所以只能返回已知条目。MatterGen 把搜索反了过来:你设定性质目标,它采样新晶体来匹配。要求体模量高于 400 GPa 时,它返回了 106 个稳定-独特-全新的结构,而参考数据集里只有 2 个。
MatterGen 的 S.U.N. 比例是多少?
基础模型的稳定-独特-全新比例是 38.57%——超过三分之一的无条件样本是稳定、彼此不同且不在训练集中的,相对能量最小值的平均位移为 0.021 埃。条件生成则从充分探索化学体系上的 83% 一直降到未探索体系上的 49%。
有 MatterGen 设计的材料被合成出来吗?
有——为 200 GPa 体模量设计的 TaCr2O6,由深圳先进技术研究院的合作者合成。实验室做出的是所预测结构的组分无序变体,实测体模量落在目标的约 20% 误差内。
MatterGen 开源吗?
开源。微软随 2025 年 1 月的 Nature 论文一起,在 GitHub 上以 MIT 协议发布了 MatterGen 代码,以及训练和微调数据。
MatterGen 把材料发现从”在目录里搜索”重新定义为”按规格设计”——而真正的开放问题已不再是扩散模型能不能画出一个看似合理的晶体,而是它画出来的有多少是真正新的、又有多少你能真的做出来。原文见 Nature。