Text-to-Image · Diffusion Models · Efficient AI
Lens: A 3.8B Text-to-Image Model Trained on ~19% of Z-Image's Compute
Microsoft's Lens is a 3.8B-parameter text-to-image diffusion model that matches 6B+ rivals while using about 19.3% of Z-Image's training compute, mostly by feeding it longer, denser captions.
Quick answer
Lens is a 3.8B-parameter text-to-image diffusion Transformer from Microsoft that reaches competitive quality against 6B+ models while consuming roughly 19.3% of the training compute reported for Z-Image — about 192K A100 GPU-hours versus Z-Image’s 314K H800 GPU-hours. The headline lever is not a new architecture but data density: Lens trains on Lens-800M, 800M image-text pairs whose GPT-4.1-generated captions average about 109 words each. It scores 0.525 on GenEval and 0.557 on OneIG (English), and generates a 1024-square image in 3.15 seconds on a single H100 (0.84 seconds for the 4-step Turbo variant).
Why dense captions are the real story
The interesting claim in Lens is that the dominant cost in training a text-to-image model is not the diffusion backbone but how much signal each image carries. Short tag-style captions force the model to see millions of images before it learns a concept. Lens instead pairs each image with a roughly 109-word GPT-4.1 caption describing layout, attributes, text content, and style, so a single training sample teaches far more per gradient step. The team argues this is why a 3.8B model converges to 6B-class quality without the matching compute budget — you pay GPT-4.1 captioning cost once, up front, instead of GPU-hours forever.
This is a claim worth scrutinizing, because “denser data beats more parameters” has been argued before and is hard to attribute cleanly. Lens at least backs it with a caption-length ablation (Figure 4) rather than asserting it.
How Lens is built
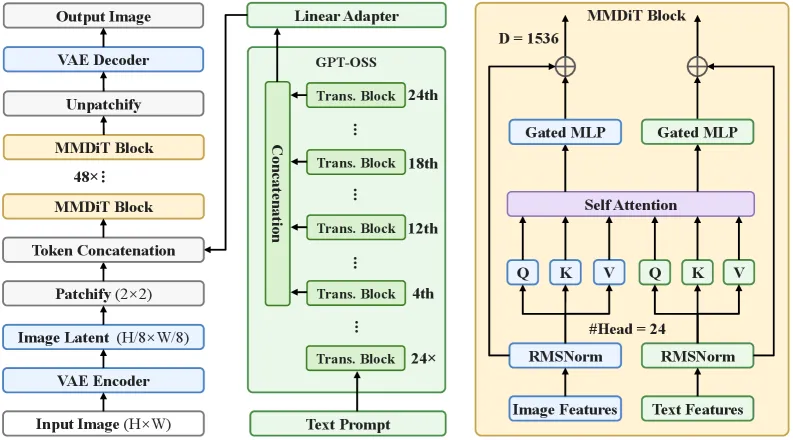
Lens is a latent diffusion Transformer in the MMDiT family: 48 MMDiT blocks with RMSNorm and RoPE. Two component choices matter. First, it uses a semantic VAE — the FLUX.2 VAE — as the tokenizer, chosen via a VAE ablation, on the argument that a latent space with semantic structure converges faster than a purely reconstructive one. Second, the text encoder is GPT-OSS, a 20B mixture-of-experts model with about 3B active parameters, replacing the usual frozen CLIP/T5 stack. Training is mixed-resolution (512, 768, and 1024 square, plus aspect ratios from 1:2 to 2:1), which lets the model generalize up to 1440-square at inference despite not training there directly.
The post-training pipeline adds reinforcement learning over a taxonomy-driven prompt set (Lens-RL-8K) and a distillation step that produces Lens-Turbo, a 4-step sampler.
Key results
- GenEval: 0.525 for the 20-step model, 0.519 for the 4-step Turbo — close enough that distillation barely costs quality.
- OneIG (English): 0.557 (20-step) vs 0.554 (Turbo).
- LongText (English): 0.930, and CVTG (NED): 0.937 — strong text-rendering scores, the area dense captions should most help.
- Training compute: ~192K A100 GPU-hours, stated as ~19.3% of Z-Image’s ~314K H800 GPU-hours.
- Latency on one H100: 3.15s for a 1024-square image at 20 steps; 0.84s for Turbo’s 4 steps.
- Parameters: 3.8B in the diffusion backbone, against 6B+ comparison models.
The benchmark margins over rivals are modest — Lens is not claiming to top every leaderboard. The claim is parity at a fraction of the cost, which is a different and arguably more useful result.
Limits and open questions
The 19.3% compute figure compares across different hardware (A100 vs H800) and only against Z-Image, so it is an illustrative ratio, not a controlled efficiency benchmark; reproducing it depends on having a GPT-4.1-grade captioner, which is itself a non-trivial cost the headline number hides. The absolute scores (GenEval 0.525) are competitive but not state-of-the-art, so “matches 6B+ models” should be read as “in the same range,” not “beats them.” Lens trains exclusively on English captions yet reports multilingual generation — an intriguing transfer effect, but one the paper demonstrates qualitatively more than it quantifies. And as with every closed-data model release, Lens-800M’s composition and licensing are described but not openly shippable, so independent reproduction is limited.
FAQ
What makes Lens more training-efficient than other text-to-image models?
Lens attributes its efficiency mainly to dense captioning: training on Lens-800M, where each of 800M images carries a roughly 109-word GPT-4.1 caption. Richer per-image supervision means the 3.8B model needs far fewer GPU-hours — about 192K A100-hours, stated as ~19.3% of Z-Image’s compute — to reach comparable quality.
How good is Lens compared to larger models?
Lens scores 0.525 on GenEval and 0.557 on OneIG (English) at 3.8B parameters, in the same range as 6B+ models rather than clearly beating them. Its strongest area is text rendering, with 0.930 on LongText and 0.937 CVTG (NED).
How fast is Lens at inference?
Lens generates a 1024-square image in 3.15 seconds on a single NVIDIA H100 with 20 sampling steps. The distilled Lens-Turbo variant does it in 0.84 seconds with only 4 steps, at almost the same benchmark scores.
What architecture and text encoder does Lens use?
Lens is a 48-block MMDiT latent diffusion Transformer using the FLUX.2 semantic VAE as tokenizer and GPT-OSS (a 20B MoE with ~3B active parameters) as the text encoder, trained at mixed resolutions and generalizing to 1440-square images.
One line: Lens bets that longer captions, not bigger models, are the cheapest path to text-to-image quality. Read the original paper on arXiv.