Eywa:让大模型智能体调用科学基础模型
Eywa 让大模型智能体把时序、表格交给 Chronos、TabPFN 等专用模型,而非塞进文本。EywaBench 上效用从 0.6154 提到 0.6558,省约 30% token。
快速答案
Eywa 是一套让语言模型智能体把非文本科学数据——时间序列、表格记录——交给 Chronos、TabPFN 这类专用基础模型处理的框架,而不是把数据压成提示词再用文本去推理。在论文自建的 EywaBench 上,单智能体版本把整体效用从 0.6154(普通 LLM 智能体)提到 0.6558,同时少用约 30% token、延迟降约 10%。编排版本以 8,335 token、48.16 秒推理时间达到 0.6746 效用,而多智能体版本要花 11,214 token、72.11 秒。
问题:语言是科学数据的有损接口
LLM 智能体擅长规划和调用工具,但它把一切都当文本读。当真正的信号藏在一段 500 点的时间序列或一张宽表里,把它序列化成 token 既贵又有损——模型永远看不到专用预测器或表格模型眼中的那份数据。论文把这点形式化为「语言接口瓶颈」:序列化会造成不可消除的贝叶斯风险差距,作者用信息论给出了下界(论文中的命题 13)。这个视角有价值——多数「LLM+工具」工作把工具当黑盒来调,而 Eywa 主张接口本身才是精度泄漏的地方。
Eywa 怎么做:Tsaheylu 神经连接
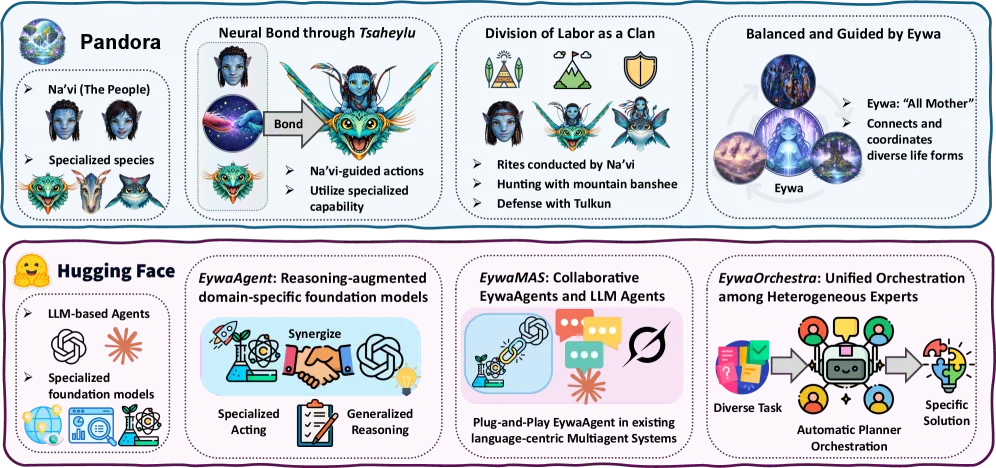
核心构件是作者命名为「Tsaheylu」的可学习 FM–LLM 连接(取自《阿凡达》里的神经链接,整套框架包括 Eywa 之名都用了这个隐喻)。它由三部分组成:一个查询编译器,把 LLM 当前状态转成基础模型可运行的配置;一个响应适配器,把模型的数值输出转回语言可用的表示;一个控制策略,决定到底值不值得调用这个专用模型。基础模型通过模型上下文协议(MCP)暴露为远程服务,于是智能体把 Chronos(时序)和 TabPFN(表格)当作有明确 schema 的接口端点。
框架分三层。EywaAgent 给一个 LLM 配一个基础模型;EywaMAS 在固定拓扑里组合若干纯语言智能体与 EywaAgent;EywaOrchestra 再加一个指挥器,按任务挑选智能体类型、语言模型、基础模型和通信拓扑——这是自动化层。
关键结果
以下数字都在 EywaBench 上,该基准由 DeepPrinciple、MMLU-Pro、fev-bench、TabArena 拼成,覆盖物理、生命、社会三大类共 9 个科学子领域和三种模态(文本、时序、表格),统一用 0–1 效用打分。
- EywaAgent vs. 单 LLM 智能体: 整体效用 0.6558 对 0.6154,token 少约 30%,延迟降约 10%。
- EywaMAS vs. 同构基线(Refine、Debate): 效用 0.6761 对 0.6294,但 token 更高(11,214 对 8,673)。
- EywaOrchestra: 效用 0.6746,几乎追平 EywaMAS,却只用 8,335 token、48.16 秒推理,而 EywaMAS 要 11,214 token、72.11 秒。自动化把多智能体多花的效率大半赚了回来。
- 分领域(gpt-5-nano): 社会科学达 0.7488、物理科学 0.6914,而生命科学只有 0.5001——提升真实但各领域并不均匀。
- 理论: 论文证明了 EywaAgent 相对纯语言智能体的严格最优风险改进(定理 3),前提是专用模型在序列化的领域输入上胜过 LLM。
为什么现在重要
智能体框架已经收敛到「LLM 编排文本工具」,但科学跑在数值和结构化数据上,那里已有专用基础模型且强过 LLM。Eywa 是较干净的一次尝试:让这两个世界通过一个有原理的接口对话,而不是字符串化的函数调用,并且同时用一个理论下界和一个跨领域基准来背书,而非单挑一个任务。
局限与存疑
绝对效用并不高——0.6558 对 0.6154 是真实但很小的提升,生命科学 0.5001 也说明这套方法救不了每个领域。动态编排被限制在有限的固定拓扑池里,指挥器只是一个做映射的 LLM 而非学出来的策略,所以「自动配置」比听起来要浅。真正接进来的只有两个基础模型(Chronos、TabPFN)和文本之外的两种模态,扩展到更多科学模态留给未来工作。结果依赖小骨干(gpt-4.1-nano、gpt-5-nano、gpt-5-mini),换上更会序列化数字的前沿模型后差距如何不清楚。而《阿凡达》主题的命名虽好记,却容易遮住一个事实:这些零件其实是相当标准的编译器/适配器/路由栈。
常见问题
Eywa 和普通的 LLM 调用工具有什么不同?
Eywa 通过可学习接口(Tsaheylu 连接:查询编译器、响应适配器、控制策略)把非文本科学数据路由给专用基础模型,而不是把时序或表格序列化进文本提示。论点是文本序列化本身就在丢信息,所以收益来自保留数据的原生格式,而非单纯多加一个工具。
Eywa 用了哪些基准和模型?
Eywa 在 EywaBench 上评测,该基准由 DeepPrinciple、MMLU-Pro、fev-bench、TabArena 拼成,覆盖物理、生命、社会三类共 9 个子领域和三种模态。接入的基础模型是时序用的 Chronos 和表格预测用的 TabPFN,LLM 骨干用 gpt-4.1-nano、gpt-5-nano、gpt-5-mini。
Eywa 把结果提升了多少?
EywaAgent 把 EywaBench 整体效用从 0.6154 提到 0.6558,同时省约 30% token。EywaOrchestra 以 8,335 token、48.16 秒推理达到 0.6746 效用,而 EywaMAS 多智能体版要 11,214 token、72.11 秒。
Eywa 能直接用于生产级科学工作吗?
不能当成开箱即用的系统。只接入了两个基础模型和两种非文本模态,编排用固定拓扑池加一个 LLM 映射的指挥器而非学出来的策略,测试也只用小骨干。它是带理论下界和基准的研究框架,而非已部署的科学平台。
一句话:Eywa 主张「LLM+工具」真正的损耗在文本接口,并展示一个可学习的 FM–LLM 连接在 EywaBench 上把效用和 token 都赚了回来。阅读 arXiv 原文。